Community Wishlist Survey 2021/Bots and gadgets
Allow loading gadgets from wikitext
- Problem: Some templates depend on JavaScript gadgets: enhanced search fields, flyout menus, and so on. Currently, if an interface administrator wants to get the gadget loaded on pages that use this template, the only option is to run a small amount of JavaScript (determining whether the full gadget should be loaded) on each and every page load, for everyone. Maybe the template is used only on one or two pages out of the tens or hundreds of thousands of pages on the wiki, yet all page loads are slowed down by it.
- Who would benefit: Readers by not having unnecessary JavaScript slowing page loads, interface admins (and even other tech-savvy users without IA right) having more straightforward way of controlling gadget loading.
- Proposed solution: Have a parser tag similar to TemplateStyles that includes a ResourceLoader module indicated in its argument.
- More comments: Care should be taken in order not to allow arbitrary code to be loaded by untrusted users (the parser tag in wikitext can be added and edited even by anonymous users). While the contents of ResourceLoader modules can be changed by only select people, probably the safest solution is to create a “namespace” (e.g.
ext.gadget.includeable.*) for this purpose within gadgets, and disallow loading any other RL module. Disallowed modules can be loaded by making them dependencies of allowed gadgets. (Dependency is safe, as gadget dependencies can be edited only by trusted interface admins.) - Phabricator tickets: phab:T17075 from 2008, T241524
- Proposer: Tacsipacsi (talk) 00:49, 26 November 2020 (UTC)
Discussion
- An alternative could be to have one default hidden gadget with the classnames/criteria -> script loading sequences... —TheDJ (talk • contribs) 12:53, 26 November 2020 (UTC)
- @TheDJ: Do you mean a gadget that decides on client side whether it should load other gadgets? This is exactly the small amount of JavaScript I mentioned and that I’d like to eliminate. (To be exact, I meant whatever way that small amount of JS is run: one default gadget, many default gadgets, Common.js etc.) This may be a small amount per gadget, but it’s not zero, and especially on Wikibooks and Wiktionaries can be many different such gadgets. —Tacsipacsi (talk) 23:51, 26 November 2020 (UTC)
 Comment I think as proposed this would make security and performance very difficult to uphold. However the idea of allowing a gadget to be enabled "by default" but limited to a subset of pages makes sense. We already support narrowing the default by skin, platform, and user rights. We could for example add support for limiting to categories. Then to initiate it from a template one would add the article to a (hidden) category. This would place the security control with the gadget configuration (the gadget definition specifies its categories, the page does not directly require a gadget), and would also encourage more re-usable logic with less effort (e.g. many articles and templates already have existing categories that you can make use of). It also means gadgets can be merged, split or renamed without their loading breaking as there would not be a direct connection between the two. Perhaps the proposal could be edited to focus more focussed on the problem and use case, and leave the implementation details to be decided by developers and other stakeholders if/when it is worked on. --Krinkle (talk) 20:30, 11 December 2020 (UTC)
Comment I think as proposed this would make security and performance very difficult to uphold. However the idea of allowing a gadget to be enabled "by default" but limited to a subset of pages makes sense. We already support narrowing the default by skin, platform, and user rights. We could for example add support for limiting to categories. Then to initiate it from a template one would add the article to a (hidden) category. This would place the security control with the gadget configuration (the gadget definition specifies its categories, the page does not directly require a gadget), and would also encourage more re-usable logic with less effort (e.g. many articles and templates already have existing categories that you can make use of). It also means gadgets can be merged, split or renamed without their loading breaking as there would not be a direct connection between the two. Perhaps the proposal could be edited to focus more focussed on the problem and use case, and leave the implementation details to be decided by developers and other stakeholders if/when it is worked on. --Krinkle (talk) 20:30, 11 December 2020 (UTC)
- Adding a ResourceLoader module from a parser function doesn't seem problematic to me performance-wise; a number of parser hooks already do that. In terms of security, the only issue I can think of is that it must not allowed to work on "safe" pages like login (via a system message; probably it shouldn't work in system messages at all).
- Categories would be nice for tracking where a script is used, but we could also just (ab)use the templatelinks table like we do for TemplateStyles. Tgr (talk) 08:51, 13 December 2020 (UTC)
- @Krinkle: If we were to use categories to decide whether or not to load a gadget, renaming gadgets would be easier, but renaming categories would be more difficult—and the consequences are far less obvious, fixing a typo in a category name would stop the gadget from working for no apparent reason. Furthermore, if one renames a category, they probably won’t be able to adjust the gadget configuration afterwards (as they’re not necessarily an interface admin). Also, gadget naming is an internal detail completely transparent for users, while category names are user-visible, so they’re much more likely needed to be changed. I think gadget renaming is already mostly impossible, as there’s no other permanent identifier for gadgets, so renaming a gadget would likely revert it back to its initial state for everyone (i.e. turn it on in case of default gadget, turn it off otherwise). I see your concerns (although I agree with Tgr in that they’re unlikely to be actual issues), but the point of easing renames is simply false IMO. Split and merger is probably really more convenient with the category-based system, but it still doesn’t outweigh the renaming issues. Also, I don’t like polluting the categories with such technicalities.
- Security-wise: what issue do you think would appear that isn’t handled by the proposed tag-based system, but would be handled by your category-based one? IAs are already in control of what could be possibly loaded (with the namespace system), while what’s actually loaded can be controlled by anyone anyway (through adding either the parser tag or the category).
- @Tgr: Entirely disabling it in messages could be the way to go, but Common.js is also disabled in these contexts, so there should be a way in MW core to determine whether risky RL modules can be loaded. (There are some MediaWiki messages like s:MediaWiki:proofreadpage_index_template that are practically templates stored in the MediaWiki namespace, and may benefit from this feature. I don’t know if these can be programmatically distinguished from the cookie prompt on the login page, which should certainly not have anything like this.) —Tacsipacsi (talk) 21:43, 14 December 2020 (UTC)
- I think it would be better to implement phab:T204201.
- That has much broader capabilities and gives more benefit at various circumstances.
- The common approach is to look for elements with certain classes after DOM has been loaded, then proceed. If that could be narrowed to a particular namespace it would save a lot of client execution time already.
- Using a category, even a hidden maintenance category, might distract attention of editors. Equipping some elements with a class is very silent.
- However, the improvements suggested in phab:T204201 may introduce more Cirrus filters like
incategoryandhastemplate(actually:transcludes). They should use underscore page titles and leave spaces as separators. - The target is to reduce the amount of gadgets to be loaded in a page but could never be useful under predictable and easily detectable conditions.
- I don’t think it is promising to introduce new Wikisyntax, new elements, new parser functions for making page contents triggering gadget execution. There are page properties and various criteria in T204201 which will deliver the same result but with less efforts and wider applicability.
--PerfektesChaos (talk) 14:21, 18 March 2021 (UTC)
Voting
 Support Would be useful to have DannyS712 (talk) 18:02, 8 December 2020 (UTC)
Support Would be useful to have DannyS712 (talk) 18:02, 8 December 2020 (UTC)- Support Sgd. —Hasley 18:31, 8 December 2020 (UTC)
- Support would be useful Teemeah (talk) 20:39, 8 December 2020 (UTC)
- Support Would be useful tufor (talk) 20:53, 8 December 2020 (UTC)
- Support Think I'd rather see a more generic such as extending templatestyle to templatescript ala phab:T8883 — xaosflux Talk 02:19, 9 December 2020 (UTC)
- Support Pols12 (talk) 02:20, 10 December 2020 (UTC)
- Support - yona B. (D) 07:12, 10 December 2020 (UTC)
- Support Aadarshashutosh (talk) 14:05, 10 December 2020 (UTC)
- Support Libcub (talk) 18:12, 10 December 2020 (UTC)
- Support BoldLuis (talk) 10:50, 11 December 2020 (UTC)
- Support James Martindale (talk) 17:48, 11 December 2020 (UTC)
- Support Ahecht (TALK
PAGE) 18:24, 11 December 2020 (UTC) - Support SD0001 (talk) 20:37, 11 December 2020 (UTC)
- Support SkSlick (talk) 19:36, 12 December 2020 (UTC)
- Support Tgr (talk) 08:12, 13 December 2020 (UTC)
- Support Edgars2007 (talk) 09:47, 13 December 2020 (UTC)
- Support Kaviraf (talk) 20:01, 13 December 2020 (UTC)
- Support Terra ❤ (talk) 11:24, 14 December 2020 (UTC)
- Support Never do anything to large numbers of pages unless it's actually necessary. — SMcCandlish ☺ ☏ ¢ >ʌⱷ҅ᴥⱷʌ< 05:06, 15 December 2020 (UTC)
- Support This proposal combines the utility of having page scripts with the security and caution of eliminating overhead for irrelevant pages. Vanisaac (talk) 01:53, 16 December 2020 (UTC)
- Support Gustmd7410 (talk) 17:26, 19 December 2020 (UTC)
- Support Regardless of the pros and cons of implementation methods, this seems like a good idea suffering from bikeshedding neglect. Faster page loads are good, wasting bandwidth is wasting resources. This page load 14 scripts. HLHJ (talk) 00:23, 20 December 2020 (UTC)
- Support Samat (talk) 21:49, 20 December 2020 (UTC)
Automatically import
- Problem: Some projects often use sites with compatible Creative Commons licenses. Usually these projects use a bot, but this takes time, some stop operating, new sites start using the Creative Commons license and others stop using it. In addition, there are many smaller wikis that are abandoned or forgotten.
- Who would benefit: Mainly Wikiquote and Wikinews, I think. But the tool would not be available to everyone, to avoid vandalism.
- Proposed solution: I am proposing the creation of a tool that allows users (not all obviously) to automatically copy content from other sites. This would help many projects to grow.
- More comments: I don't know if it has been proposed before, I await comments…
- Phabricator tickets:
- Proposer: Edu! (talk) 15:51, 18 November 2020 (UTC)
Discussion
- I think this will be highly useful. I know several compatible wikis that are used as sources of content. However, not being currently able to do the import as described in the proposal mean we can't get the best attribution for the content. We rely on third parties to track the individual work on the article. If I recall correctly, there was a problem with non-Wikimedia wikis due to different user bases (if you import edition ABCD done by User:XYWZ, the software considers the user:XYWZ in the end wiki instead of the source wiki). However, I think it should be technically feasible to adapt to wikis using a different repository of users.--FAR (talk) 10:04, 29 November 2020 (UTC)
- How is this different from Special:Export/Import and related functionality? --Tgr (talk) 06:53, 14 December 2020 (UTC)
Voting
- Support UncleMartin (talk) 01:31, 9 December 2020 (UTC)
- Support Omda4wady (talk) 07:25, 9 December 2020 (UTC)
- Support If these sites use Creative Commons as a license, the proposal is excellent! WikiFer msg 22:47, 10 December 2020 (UTC)
- Support Strong support. Can help a lot to save time. BoldLuis (talk) 10:40, 11 December 2020 (UTC)
- Support Anonyme314159 (talk) 18:36, 15 December 2020 (UTC)
- Support Sounds good but a bit broad. Are we talking imports to Wikisource? Commons? A frequent usecase is when a site provider has just re-licensed their images or whatever under a more restrictive license; since they can't cancel the old license we can rescue the material and re-host it. HLHJ (talk) 00:15, 20 December 2020 (UTC)
- Support Juan90264 (talk) 03:08, 21 December 2020 (UTC)
- Support S8321414 (talk) 14:08, 21 December 2020 (UTC)
Artificial Intelligence Spam hunter
- Problem: Spam is replacing vandalism as our biggest problem
- Who would benefit: Everyone. But probably first the English Wikipedia
- Proposed solution: Use the articles and edits that have been deleted as spam to train an Artificial Intelligence bot to identify spam, tag it for deletion or revert it where it is certain it is spam and bring it to human attention where it is less confident
- More comments:
- Phabricator tickets:
- Proposer: WereSpielChequers (talk) 22:07, 29 November 2020 (UTC)
Discussion
- I'm a little fuzzy on the distinction between spam and vandalism. Aren't edits that are reverted as spam considered vandalism and used to train ClueBotNG? Is this just about pages rather than edits, then? {{u|Sdkb}} talk 04:26, 9 December 2020 (UTC)
- Notice some wikis already have a "draftquality" model available in ORES, which allows using the API to detect new pages which would be deleted due to SPAM. For example, this is the prediction ORES API provides for the page created at w:en:Special:PermaLink/988066833. The API can be used by scripts such as User:He7d3r/Tools/DraftAndArticleQualityCore.js (by adapting the config used at ptwiki), to add icons as in this image. Helder 20:59, 10 December 2020 (UTC)
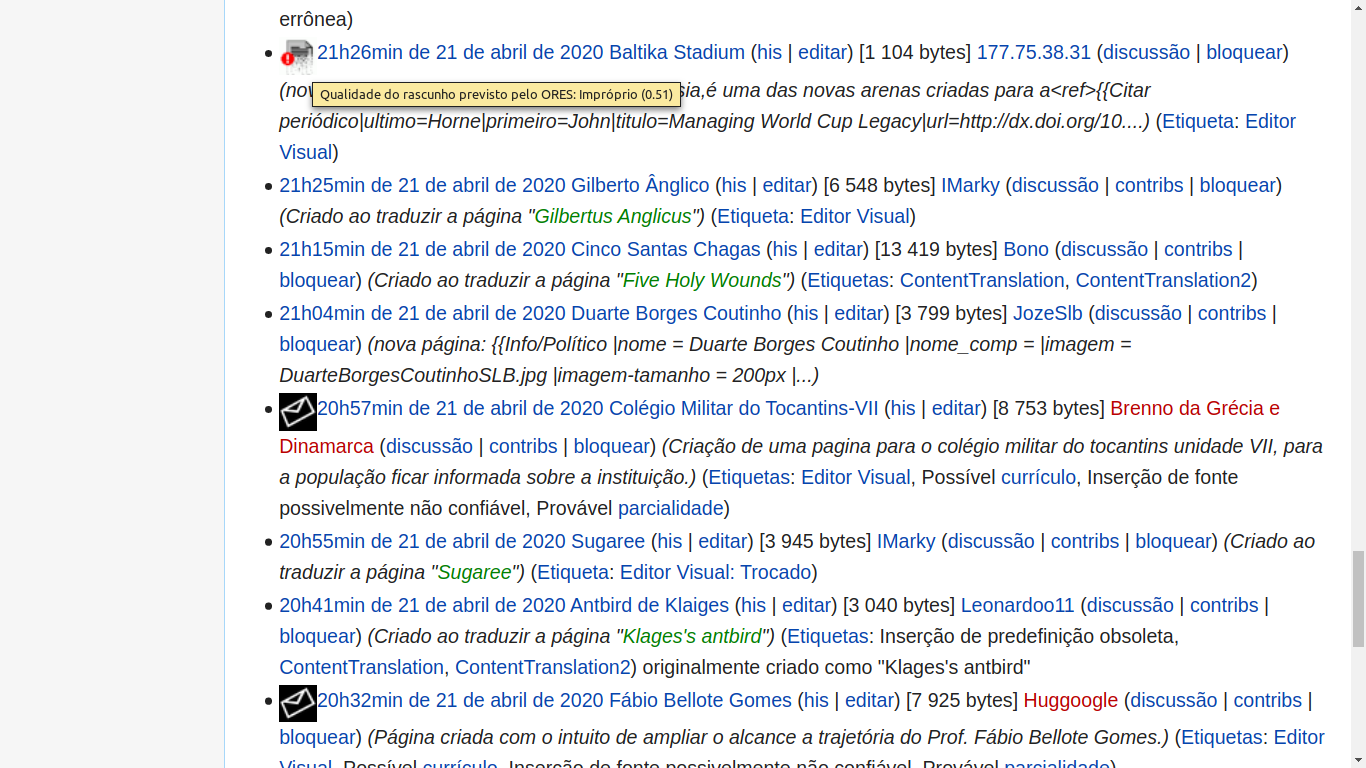{kind=link}
Voting
- Support Waddie96 (talk) 18:36, 8 December 2020 (UTC)
- Support —MarcoAurelio (talk) 20:04, 8 December 2020 (UTC)
- Support CrystallineLeMonde (talk) 20:21, 8 December 2020 (UTC)
- Support N8wilson (talk) 20:30, 8 December 2020 (UTC)
- Support Ponor (talk) 22:24, 8 December 2020 (UTC)
- Support Hanif Al Husaini (talk) 01:53, 9 December 2020 (UTC)
- Support Keepcalmandchill (talk) 02:17, 9 December 2020 (UTC)
- Support Ottawajin (talk) 05:10, 9 December 2020 (UTC)
- Support Xgeorg (talk) 06:52, 9 December 2020 (UTC)
- Support 1Mmarek (talk) 11:35, 9 December 2020 (UTC)
- Support JASpencer (talk) 16:29, 9 December 2020 (UTC)
- Support Lirazelf (talk) 16:40, 9 December 2020 (UTC)
- Support Rafael (stanglavine) msg 18:48, 9 December 2020 (UTC)
- Support TheAmerikaner (talk) 20:26, 9 December 2020 (UTC)
- Support YuriNikolai (talk) 22:14, 9 December 2020 (UTC)
- Support NMaia (talk) 01:22, 10 December 2020 (UTC)
- Support Would be interested in helping to develop this, and have been planning a similar project to see if something like this would be feasible. JPxG (talk) 05:45, 10 December 2020 (UTC)
- Support. Meiræ 18:49, 10 December 2020 (UTC)
- Support. Helder 20:59, 10 December 2020 (UTC)
- Support Excellent proposal aimed at combating spam, with human evaluation when not very evident. WikiFer msg 23:29, 10 December 2020 (UTC)
 Oppose. Humans must give a reason afther this, to delete. BoldLuis (talk) 10:39, 11 December 2020 (UTC)
Oppose. Humans must give a reason afther this, to delete. BoldLuis (talk) 10:39, 11 December 2020 (UTC)- Support ArnabSaha (talk) 15:14, 11 December 2020 (UTC)
- Support SD0001 (talk) 20:35, 11 December 2020 (UTC)
- Support Quebec99 (talk) 21:09, 11 December 2020 (UTC)
- Support Wikibenchris (talk) 08:46, 13 December 2020 (UTC)
- Support.--HakanIST (talk) 08:06, 14 December 2020 (UTC)
- Support —Thanks for the fish! talk•contribs 22:34, 14 December 2020 (UTC)
- Support Would be a great addition to the capabilities in m:User:LiWa3 (which are currently purely statistical). A bot could read from the feeds of LiWa3, or I could possibly hook it into an external process. Dirk Beetstra T C (en: U, T) 07:42, 15 December 2020 (UTC)
- Support LucySky (talk) 19:52, 15 December 2020 (UTC)
- Support Ææqwerty (talk) 08:53, 16 December 2020 (UTC)
- Support But only this makes sense in terms of what ORES already can or cannot do, I'd rather it wasn't an unrelated standalone tool/bot Base (talk) 19:47, 17 December 2020 (UTC)
- Support Owleksandra (talk) 19:48, 17 December 2020 (UTC)
- Support If this can be done, it would be useful. This might be even more difficult, but detecting shillsockrings (is that a word? Orangemoody and Wiki-PR and the like) would be even more useful. HLHJ (talk) 02:19, 20 December 2020 (UTC)
- Support AdaHephais (talk) 05:47, 20 December 2020 (UTC)
- Support —2d37 (talk) 10:26, 21 December 2020 (UTC)
- Support David1010 (talk) 11:58, 21 December 2020 (UTC)
DabFix
- Problem: The DabFix tool for rapidly populating disambiguation pages is no longer available.
- Who would benefit: Editors who create disambiguation pages.
- Proposed solution: Create an in-house version of DabFix capable of populating disambiguation pages with appropriate information (e.g., birth and death dates of human subjects, and short descriptions of their significance).
- More comments:
- Phabricator tickets:
- Proposer: BD2412 T 00:24, 25 November 2020 (UTC)
Discussion
Yes, none of these tools seem to work anymore, and they have always been erratic. Too bad, because they were very helpful tools: Dabfix, Dabsolver, Commonfixes.
Vmavanti (talk) 18:39, 8 December 2020 (UTC)
- I'd add Dablinks, which is the tool I use most. (Example page: [1].) Certes (talk) 16:45, 9 December 2020 (UTC)
- Code for Dablinks could be reused to warn when linking to disambiguation pages. Certes (talk) 17:11, 9 December 2020 (UTC)
The tools are not currently available via their usual IP address. Even if they return, they may be unstable, which increases the priority of this wish. I have a backup of the source code, but no licence to use or deploy it. Certes (talk) 18:21, 25 December 2020 (UTC)
Voting
- Support Waddie96 (talk) 18:38, 8 December 2020 (UTC)
- Support Vmavanti (talk) 18:40, 8 December 2020 (UTC)
- Support Movses (talk) 19:03, 8 December 2020 (UTC)
- Support Count Count (talk) 19:40, 8 December 2020 (UTC)
- Support Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 20:26, 8 December 2020 (UTC)
- Support N8wilson (talk) 20:31, 8 December 2020 (UTC)
- Support The tools still work via IP address but a more widely supported version would be welcome. Certes (talk) 20:47, 8 December 2020 (UTC)
- Support Hanif Al Husaini (talk) 01:50, 9 December 2020 (UTC)
- Support * Pppery * it has begun 01:53, 9 December 2020 (UTC)
- Support I haven't done work in this area, but this proposal seems like it will help out others who have and want to do more. {{u|Sdkb}} talk 04:24, 9 December 2020 (UTC)
- Support Tmv (talk) 09:52, 9 December 2020 (UTC)
- Support YES! We need this ASAP Oaktree b (talk) 16:24, 9 December 2020 (UTC)
- Support Would be helpful in dealing with the volume of dablinks Rodw (talk) 17:32, 9 December 2020 (UTC)
- Support Emanuele676 (talk) 00:17, 10 December 2020 (UTC)
- Support MichaelMaggs (talk) 08:46, 10 December 2020 (UTC)
- Support this would be quite helpful Libcub (talk) 18:14, 10 December 2020 (UTC)
- Support Tool needed to help creators of disambiguation pages. WikiFer msg 23:12, 10 December 2020 (UTC)
- Support Much time saved. BoldLuis (talk) 10:43, 11 December 2020 (UTC)
- Support Alexcalamaro (talk) 14:18, 11 December 2020 (UTC)
- Support Izno (talk) 15:29, 11 December 2020 (UTC)
- Support Watty62 (talk) 17:01, 11 December 2020 (UTC)
- Support much needed. with better multilingual support please Aswn (talk) 17:47, 11 December 2020 (UTC)
- Support Ahecht (TALK
PAGE) 18:21, 11 December 2020 (UTC) - Support Redalert2fan (talk) 00:10, 12 December 2020 (UTC)
- Support DGG (talk) 00:52, 12 December 2020 (UTC)
- Support ~ Amory (u • t • c) 19:47, 13 December 2020 (UTC)
- Support --Luan (discussão) 19:54, 16 December 2020 (UTC)
- Support I am actually working on a bot that would suggest where a disambiguation page would be needed (when there are several pages with the same name but the parenthesis part and where neither in the cluster is a disambiguation already), but my progress is rather slow. I am not sure what the tool mentioned was doing, but I definitely support any reasonable tool development related to better management of disambiguation pages. Base (talk) 19:52, 17 December 2020 (UTC)
- Support Owleksandra (talk) 19:52, 17 December 2020 (UTC)
- Support Golmore (talk) 11:03, 18 December 2020 (UTC)
- Support Never used this tool, however, seems it will benefit all VKG1985 (talk) 17:29, 18 December 2020 (UTC)
- Support The tool is very much alive, and it's accessible from http://69.142.160.183/~dispenser/view/Dabfix. However, some important functions (like the missing entries one) relied on some feature on the mediawiki side (or was it toolforge?) which apparently got disabled around March–April 2019 (the feature had to do with user tables or something like that). If that feature could be enabled again, that would be great. Uanfala 22:13, 19 December 2020 (UTC)
- Support AdaHephais (talk) 05:49, 20 December 2020 (UTC)
- Support WikiAviator (talk) 11:20, 20 December 2020 (UTC)
- Support Juan90264 (talk) 03:10, 21 December 2020 (UTC)
Improve Auto-wiki-browser
- Problem: Auto-wiki-browser's resolution is very low and cannot display pages in visual diff mode.
- Who would benefit: AWB users
- Proposed solution: Add support for visual diff mode and visual editor in AWB and improve it's resolution. It would also be great if a web-app version is available.
- More comments:
- Phabricator tickets:
- Proposer: WikiAviator (talk) 06:25, 17 November 2020 (UTC)
Discussion
- Isn't that maintained by users, not MediaWiki/WMF? DemonDays64 (talk) 09:07, 17 November 2020 (UTC)
- It is, however it has never been an obstacle for CommTech. A more serious problem is that AWB is developed on Windows while WMF engineers only use Mac/Linux. Max Semenik (talk) 10:29, 17 November 2020 (UTC)
- Oh come on, I'm sure we can fund some cloud instances with Windows from an external provider.
- Although I remember seeing a web port at some point. Don't remember where I saw it and if it shares some codebase with the Windows app. Maybe working on that would be helpful?--Strainu (talk) 11:43, 17 November 2020 (UTC)
- Yeah I think so. For working on CommTech, I don't see it as a problem because WMF can always modify it (assuming it is released on an open license) and make an officially-maintained version of it. Also, it would be better if more users could use AWB.WikiAviator (talk) 13:36, 17 November 2020 (UTC)
- AWB is a community maintained, yes. I have been trying to rework it, but its codebase is so outdated, and there's a huge lack of comments in general in the code which makes it hard to see what does what. However, I am trying to swap out the Internet Explorer elements with Chromium (CEFSharp), but I can't make any promises with how feasible it is, and whether or not it'd just be better for somebody to start it all again from scratch. Ed6767 (talk) 14:46, 17 November 2020 (UTC)
- I think we can start this from scratch as a Web-based application (for easier access) based on Auto-Ed, that would be easier for the developers in the community as well as the WMF. WikiAviator (talk) 06:14, 18 November 2020 (UTC)
- AWB is a community maintained, yes. I have been trying to rework it, but its codebase is so outdated, and there's a huge lack of comments in general in the code which makes it hard to see what does what. However, I am trying to swap out the Internet Explorer elements with Chromium (CEFSharp), but I can't make any promises with how feasible it is, and whether or not it'd just be better for somebody to start it all again from scratch. Ed6767 (talk) 14:46, 17 November 2020 (UTC)
- Yeah I think so. For working on CommTech, I don't see it as a problem because WMF can always modify it (assuming it is released on an open license) and make an officially-maintained version of it. Also, it would be better if more users could use AWB.WikiAviator (talk) 13:36, 17 November 2020 (UTC)
- .NET 5 is open source and can now be downloaded for Mac and Linux.[2]. I assume there is a compiler available for Mac/Linux development. (And why does WMF only use Mac/Linux? Is that even relevant if we have at least one volunteer compiling to Windows? Completely offtopic, I know. :) --Izno (talk) 05:48, 18 November 2020 (UTC)
- Historically Windows is not a very developer-friendly OS (considering everything we deploy to is Linux-based). But times have changed, as I understand it. Windows can now do Linux-y things too, and I know several WMF and WMDE devs who use Windows. Regardless, I don't think we should perpetuate AWB as a Windows application by adding more features to it. If it's true .NET can be used cross-platform, as you say, getting that working is step #1, but it sounds like a complete rewrite is the better long-term option which is surely out of scope :(
- That said, @WikiAviator have you tried JWB, as Fastily mentions below? That is a web-based version that I think would be much easier for us to contribute to (if the maintainer is open to outside contributions). MusikAnimal (WMF) (talk) 22:03, 21 November 2020 (UTC)
- I've tried it lately and it has problems making lists (can't make list for new pages), but the foundation is solid (it works smoothly overall). I think we can collaborate with the maintainer so we can revamp and publicly release it as official commtech (like Huggle and AWB). I agree that the web version would be easier for us compared to the Windows version (running discontinued IE). If JWB is stable enough, we can abandon AWB altogether. WikiAviator (talk) 13:29, 23 November 2020 (UTC)
- The core of .NET 5 is open-source and cross-platform, but this doesn’t mean everything built on this core is as well. Windows Forms, used by AWB, is still Windows-only in .NET 5. Although it’s possible in theory to get current AWB work on Linux (with Mono and some other additional software), I haven’t been able to do so yet. GTK# is an open-source GUI alternative, but it looks like a dead project at a glance. As far as I understand, .NET MAUI is truly cross-platform and under heavy development, but this heavy development means that its general availability is planned in a year, so while porting AWB to it may be the way to go, it probably won’t happen in 2021. —Tacsipacsi (talk) 00:24, 26 November 2020 (UTC)
- It is, however it has never been an obstacle for CommTech. A more serious problem is that AWB is developed on Windows while WMF engineers only use Mac/Linux. Max Semenik (talk) 10:29, 17 November 2020 (UTC)
- There is a browser based version of AWB: w:User:Joeytje50/JWB -FASTILY 05:11, 18 November 2020 (UTC)
- There is a Phabricator task for that. 𝟙𝟤𝟯𝟺𝐪𝑤𝒆𝓇𝟷𝟮𝟥𝟜𝓺𝔴𝕖𝖗𝟰 (𝗍𝗮𝘭𝙠) 22:21, 21 November 2020 (UTC)
- Clarification: Wikipedia:AutoWikiBrowser. BoldLuis (talk) 10:54, 11 December 2020 (UTC)
Voting
- Support Would be nice if somebody from WMF steps in, since it is a fairly extensively used tool. Sannita - not just another it.wiki sysop 19:22, 8 December 2020 (UTC)
- Support Quarz (talk) 20:05, 8 December 2020 (UTC)
- Support Good idea شادي (talk) 22:36, 8 December 2020 (UTC)
- Support anything for better usabilityh Leftowiki (talk) 00:37, 9 December 2020 (UTC)
- Support Hanif Al Husaini (talk) 01:49, 9 December 2020 (UTC)
- Support - Darwin Ahoy! 01:40, 10 December 2020 (UTC)
- Support so much quality improvement from this tool Blue Rasberry (talk) 01:49, 10 December 2020 (UTC)
- Support Helder 20:34, 10 December 2020 (UTC)
- Support Srđan (talk) 22:11, 10 December 2020 (UTC)
- Support Better view diff, in addition to using the web-app tool for those who do not download AWB. WikiFer msg 23:20, 10 December 2020 (UTC)
- Support --Andyrom75 (talk) 19:05, 11 December 2020 (UTC)
- Support Already a great tool and if issues could be fixed by updating / rewriting the code base that would be a huge long term boon. Jamesmcmahon0 (talk) 08:37, 13 December 2020 (UTC)
- Support Jurbop (talk) 07:22, 15 December 2020 (UTC)
- Support Shenme (talk) 04:52, 17 December 2020 (UTC)
- Support Temp3600 (talk) 17:39, 17 December 2020 (UTC)
- Support It will benefit all of us VKG1985 (talk) 17:15, 18 December 2020 (UTC)
- Support Juan90264 (talk) 07:52, 21 December 2020 (UTC)
- Support David1010 (talk) 12:03, 21 December 2020 (UTC)
API for deleted title search
- Problem: Some time ago, it became possible to search the archive table for titles of deleted pages - https://en.wikipedia.org/w/index.php?prefix=%28company%29&title=Special%3AUndelete&fuzzy=1 (admins only). This functionality is not accessible through the API and therefore cannot be incorporated into bots and gadgets used by administrators. As a consequence, this limits the discoverability of reposts under a slightly different title (a very common abuse tactic).
- Who would benefit: Admins, patrollers, bot operators
- Proposed solution: See above. A module is added to the Action API that allows searching for deleted titles.
- More comments:
- Phabricator tickets: T192023
- Proposer: MER-C (talk) 17:47, 21 November 2020 (UTC)
Discussion
Voting
- Support Would be useful to have DannyS712 (talk) 18:02, 8 December 2020 (UTC)
- Support This will, for example, help salted pages from being recreated under a similar name (per nom) Opalzukor (talk) 19:40, 8 December 2020 (UTC)
- Support CrystallineLeMonde (talk) 20:22, 8 December 2020 (UTC)
- Support * Pppery * it has begun 01:53, 9 December 2020 (UTC)
- Support Sgd. —Hasley 13:41, 9 December 2020 (UTC)
- Support MER-C (talk) 20:07, 9 December 2020 (UTC)
- Support YuriNikolai (talk) 22:13, 9 December 2020 (UTC)
- Support JPxG (talk) 05:44, 10 December 2020 (UTC)
- Support Libcub (talk) 18:17, 10 December 2020 (UTC)
- Support Alexcalamaro (talk) 22:20, 10 December 2020 (UTC)
- Support It makes it easier to search for deleted pages. WikiFer msg 22:55, 10 December 2020 (UTC)
- Support — Bilorv (talk) 00:54, 11 December 2020 (UTC)
- Support Krinkle (talk) 20:21, 11 December 2020 (UTC)
- Support DGG (talk) 00:50, 12 December 2020 (UTC)
- Support -- the wub "?!" 18:25, 13 December 2020 (UTC)
- Support —Thanks for the fish! talk•contribs 22:33, 14 December 2020 (UTC)
- Support Base (talk) 19:38, 17 December 2020 (UTC)
- Support Owleksandra (talk) 19:39, 17 December 2020 (UTC)
Inform gadget developers of errors in their gadgets/scripts
- Problem: Wikimedia projects now have Logstash which allows us to log client-side errors experienced by our users. Since the information is in logstash, only LDAP users can view this information. My proposal is to allow gadget developers to see these errors for their gadgets in anonymized form.
- Who would benefit: All gadget developers will have a better insight into how their gadgets are working and users using the gadgets will experience fewer bugs.
- Proposed solution: With LDAP credentials I can filter file url results to show only errors relating to my gadget. Without LDAP however, I can't see this. One option would be to automate the table creation manually being created onUser:Jdlrobson/User_scripts_with_client_errors#Top_errors
- More comments:
- Phabricator tickets:
- Proposer: Jdlrobson (talk) 16:14, 18 November 2020 (UTC)
Discussion
Voting
- Support Would be useful to have DannyS712 (talk) 18:02, 8 December 2020 (UTC)
- Support Matěj Suchánek (talk) 19:21, 8 December 2020 (UTC)
- Support Iniquity (talk) 23:48, 8 December 2020 (UTC)
- Support – Ammarpad (talk) 04:30, 9 December 2020 (UTC)
- Support Thomas Kinz (talk) 09:28, 9 December 2020 (UTC)
- Support Sohom Datta (talk) 11:41, 9 December 2020 (UTC)
- Support YuriNikolai (talk) 22:15, 9 December 2020 (UTC)
- Support NMaia (talk) 01:22, 10 December 2020 (UTC)
- Support - yona B. (D) 07:13, 10 December 2020 (UTC)
- Support Euro know (talk) 11:04, 10 December 2020 (UTC)
- Support MarsInSVG (talk) 14:48, 10 December 2020 (UTC)
- Support Libcub (talk) 18:16, 10 December 2020 (UTC)
- Support Excellent for developers to check for errors in gadgets. WikiFer msg 23:15, 10 December 2020 (UTC)
- Support Frozenmadness (talk) 23:20, 11 December 2020 (UTC)
- Support tufor (talk) 16:57, 12 December 2020 (UTC)
- Support Gce (talk) 18:46, 12 December 2020 (UTC)
- Support Edgars2007 (talk) 09:49, 13 December 2020 (UTC)
- Support ~ Amory (u • t • c) 19:47, 13 December 2020 (UTC)
- Support Lomrjyo (talk) 19:22, 14 December 2020 (UTC)
- Support The sooner the bug is discovered, the higher the chances that the script author remembers their intents clearly enough to be able to fix it. Tacsipacsi (talk) 21:58, 14 December 2020 (UTC)
- Support —Thanks for the fish! talk•contribs 22:34, 14 December 2020 (UTC)
- Support Rzuwig► 14:15, 15 December 2020 (UTC)
- Support Shenme (talk) 04:53, 17 December 2020 (UTC)
- Support Joalbertine (talk) 14:28, 17 December 2020 (UTC)
- Support Temp3600 (talk) 17:37, 17 December 2020 (UTC)
- Support Base (talk) 19:31, 17 December 2020 (UTC)
- Support VKG1985 (talk) 17:25, 18 December 2020 (UTC)
- Support WikiAviator (talk) 11:16, 20 December 2020 (UTC)
- Support 郑洲扬 (talk) 13:20, 20 December 2020 (UTC)
- Support Juan90264 (talk) 03:09, 21 December 2020 (UTC)
- Support S8321414 (talk) 14:08, 21 December 2020 (UTC)
Bot to input the proper class for all wiki projects
- Problem: That most wikiprojects aren’t put in their proper class or importance
- Who would benefit: Editors who want to know what needs improving upon, in addition to users who search through projects
- Proposed solution: A bot should be created in order to fill out the classes and importance of all wikiprojects, mainly the classes because it can be read off other wikiprojects and it is already automated in.
- More comments:
- Phabricator tickets:
- Proposer: Bigmike2346 02:30, 17 November 2020 (UTC)
Discussion
- @Bigmike2346: Hello and thanks for participating in the survey! I have corrected the formatting of your proposal. If you could, please fill in the "Problem" and "Who would benefit" questions. Thanks! MusikAnimal (WMF) (talk) 03:28, 17 November 2020 (UTC)
- I believe this is a matter for specific projects to discuss on a case-by-case basis, as each WikiProject has a different purpose. If the proposal is to automatically assess class then many editors would object, thinking that only a human can properly assess each class criterion. If the proposal is just to copy over classes/importances where they occur for other projects on the same talk page then this again is flawed, as importances can vary across projects and WikiProjects may even have different levels of strictness for different classes. A user-maintained bot could serve whatever action is required, rather than WMF involvement. — Bilorv (talk) 17:55, 17 November 2020 (UTC)
- Class at least is pretty universal for most pages. In that regard we used to have a bot on en.WP at least that would duplicate classes from one banner to another. (So I agree with the final comment.) --Izno (talk) 19:25, 17 November 2020 (UTC)
Voting
- Oppose Carn (talk) 05:22, 10 December 2020 (UTC)
- Oppose I believe that each local project should discuss receiving this information for WikiProjects. WikiFer msg 23:33, 10 December 2020 (UTC)
- Oppose Every language is different. This proposal is impossible to do. - Bzh-99 (talk) 12:30, 12 December 2020 (UTC)
- Oppose --WTM (talk) 00:34, 15 December 2020 (UTC)
- Support AdaHephais (talk) 05:50, 20 December 2020 (UTC)
 Strong support If you mean categories, then yep. I myself don't always sort my articles. Red-back spider (talk) 10:09, 20 December 2020 (UTC)
Strong support If you mean categories, then yep. I myself don't always sort my articles. Red-back spider (talk) 10:09, 20 December 2020 (UTC)- Support S8321414 (talk) 14:07, 21 December 2020 (UTC)
Gadgets improvements
- Problem: Gadgets are hard to develop and maintain, even more so for smaller communities and non-English wikis
- Who would benefit: Anyone who uses or develops gadgets
- Proposed solution: See below
- More comments:
- Phabricator tickets: a bunch
- Proposer: DannyS712 (talk) 06:39, 23 November 2020 (UTC)
Work on Gadgets 2.0 is stalled, and the Gadget and Gadget definition namespaces are registered and reserved, but not used for anything. The following parts of the old roadmap (mw:Extension:Gadgets/Roadmap#Gadgets 2.0) and tracking task (phab:T31272) should be prioritized
- "No more manual editing of gadgets definition, everything should have its GUI to change the underlying JSON definition" - add an interface to manage the gadget definitions (rights required, scripts and styles to load, messages, default enabled, whether the gadget is hidden, etc.)
- Gadget code and definitions should move out of the mediawiki namespace to the dedicated gadget and gadget definitions namespace (see the example use of the gadget definitions namespace at mw:Extension:Gadgets#Using Gadget Definition Namespace, though as noted above it shouldn't need to be edited manually as json, but rather via a GUI)
- "Structured localization framework for gadgets" - phab:T238386
Discussion
Is this complete and deploy Gadgets 2.0? "Gadgets improvements" suggests broader topic but the proposal seems limited to the extension. – Ammarpad (talk) 04:36, 24 November 2020 (UTC)
- Essentially, yes, but since its not very clear how "Gadgets 2.0" is currently scoped/defined, I listed the key issues that I thought should be addressed DannyS712 (talk) 04:58, 24 November 2020 (UTC)
- Much wanted. It had promising development in the past but then it silenced.
- For localization improvements, Community Wishlist Survey 2021/Bots and gadgets/Easy and effective way to translate gadgets and userscripts was also proposed. --Matěj Suchánek (talk) 08:32, 24 November 2020 (UTC)
- Gadgets 2.0 includes a real localization and translation system. Kaldari (talk) 18:38, 8 December 2020 (UTC)
- The Gadgets 2.0 code is pretty much complete. The main part that needed to be finished was the code for migrating old gadgets to Gadgets 2.0, and also just more testing and polish to make sure such a big feature change goes smoothly. Since Gadgets 2.0 never had a Product Manager or QA Engineer those last steps never happened. I bet CommTech could get it finished though! Kaldari (talk) 18:38, 8 December 2020 (UTC)
Voting
- Support -- CptViraj (talk) 18:10, 8 December 2020 (UTC)
- Support Kaldari (talk) 18:39, 8 December 2020 (UTC)
- Support <3 Matěj Suchánek (talk) 19:18, 8 December 2020 (UTC)
- Support I'd love them to be global, but in the meantime... Sannita - not just another it.wiki sysop 19:23, 8 December 2020 (UTC)
- Support Pyroforos (talk) 19:27, 8 December 2020 (UTC)
- Support Pmau (talk) 20:10, 8 December 2020 (UTC)
- Support Iniquity (talk) 23:47, 8 December 2020 (UTC)
- Support Shizhao (talk) 02:48, 9 December 2020 (UTC)
- Support – Ammarpad (talk) 04:32, 9 December 2020 (UTC)
- Support Tmv (talk) 07:43, 9 December 2020 (UTC)
- Support Kpjas (talk) 10:45, 9 December 2020 (UTC)
- Support Sgd. —Hasley 13:24, 9 December 2020 (UTC)
- Support ‐‐1997kB (talk) 13:56, 9 December 2020 (UTC)
- Support Good idea, to simplify the process Oaktree b (talk) 16:23, 9 December 2020 (UTC)
- Support — putnik 18:50, 9 December 2020 (UTC)
- Support Cabayi (talk) 20:19, 9 December 2020 (UTC)
- Support GeneralNotability (talk) 23:47, 9 December 2020 (UTC)
- Support - Darwin Ahoy! 01:40, 10 December 2020 (UTC)
- Support First step was made, we need second Carn (talk) 05:18, 10 December 2020 (UTC)
- Support β16 - (talk) 11:49, 10 December 2020 (UTC)
- Support Libcub (talk) 18:15, 10 December 2020 (UTC)
- Support Helder 20:33, 10 December 2020 (UTC)
- Support ProcrastinatingReader (talk) 00:27, 11 December 2020 (UTC)
- Support Gnangarra (talk) 00:59, 11 December 2020 (UTC)
- Support Evad37 (talk) 03:18, 11 December 2020 (UTC)
- Support --Zache (talk) 03:28, 11 December 2020 (UTC)
- Support --valepert (talk) 12:27, 11 December 2020 (UTC)
- Support MichaelSchoenitzer (talk) 14:15, 11 December 2020 (UTC)
- Support Izno (talk) 15:28, 11 December 2020 (UTC)
- Support Bencemac (talk) 16:15, 11 December 2020 (UTC)
- Support Arnd (talk) 16:37, 11 December 2020 (UTC)
- Support Theklan (talk) 17:38, 11 December 2020 (UTC)
- Support The Gadgets 2.0 code is pretty much complete ... just more testing and polish 🚢🚢🚢 czar 17:40, 11 December 2020 (UTC)
- Support I concur, --Krinkle (talk) 20:20, 11 December 2020 (UTC)
- Support It will be very important for developers. WikiFer msg 22:52, 11 December 2020 (UTC)
- Support Strainu (talk) 09:45, 12 December 2020 (UTC)
- Support Francois-Pier (talk) 11:54, 12 December 2020 (UTC)
- Support SkSlick (talk) 19:33, 12 December 2020 (UTC)
- Support Novak Watchmen (talk) 19:32, 13 December 2020 (UTC)
- Support A usable i18n framework is a must-have, but not having to worry about breaking all gadgets with an incorrect edit to MediaWiki:gadgets-definition would also be a huge improvement. Tacsipacsi (talk) 22:03, 14 December 2020 (UTC)
- Support —Thanks for the fish! talk•contribs 22:35, 14 December 2020 (UTC)
- Support — Draceane talkcontrib. 12:52, 15 December 2020 (UTC)
- Support Rzuwig► 14:14, 15 December 2020 (UTC)
- Support Mihir Narayanan (talk) 02:34, 16 December 2020 (UTC)
- Support Joalbertine (talk) 14:22, 17 December 2020 (UTC)
- Support Julián L. Páez 03:50, 21 December 2020 (UTC)
- Support Goombiis (talk) 08:25, 21 December 2020 (UTC)
- Support David1010 (talk) 12:01, 21 December 2020 (UTC)
- Support S8321414 (talk) 14:07, 21 December 2020 (UTC)
Talk page archiving bot updating incoming links
- Problem: When a talk page thread gets archived, all incoming links into the thread get broken, making it very difficult to follow old threads, which often contain useful information for current discussions. In the English Wikipedia we have ClueBot III which claims to fix up links while archiving (en:User:ClueBot_III#Keeping_linked), but in reality it unfortunately does this only to a very limited extent (links from other pages). The more important links from the same page (from other threads or from inside the very thread to be archived, as well as links from threads already archived) don't get updated.
- Who would benefit: All Wikipedians participating in talk page discussions
- Proposed solution: Enhance ClueBot III or provide a new universal archiving bot fixing up all links while archiving automatically. While detecting links from the same page might be more difficult than to detect links from other pages, it certainly isn't impossible.
- More comments:
- Phabricator tickets:
- Proposer: Matthiaspaul (talk) 02:46, 26 November 2020 (UTC)
Discussion
- As an alternative, there's also w:User:SD0001/find-archived-section which very conveniently searches archives when following a broken link. It's available as a gadget on English Wikipedia. I'm not sure something like this belongs in MediaWiki and/or an extension, but we could globalize/localize the gadget to make it more easily available to all wikis. MusikAnimal (WMF) (talk) 14:44, 26 November 2020 (UTC)
- Yeah, thanks for providing the link. Unfortunately, scripts like this cannot be used by people who (must) have JavaScript disabled for security reasons (or are using browsers not supporting it). So, a more general solution is still needed, ideally one which fixes the problem at its root (that is, in the moment when the problem is created), not at a later point in time when it may be difficult to put the pieces together reliably.
- --Matthiaspaul (talk) 14:52, 26 November 2020 (UTC) (updated 12:59, 13 December 2020 (UTC))
- Thanks for the link, had no idea this existed. — Bilorv (talk) 00:44, 11 December 2020 (UTC)
Voting
- Support Shoeper (talk) 18:45, 8 December 2020 (UTC)
- Support w:User:SD0001/find-archived-section takes care of this problem in most instances, but it's still an issue for newcomers who may not have enabled the gadget and still a minor inconvenience even for those with the gadget. {{u|Sdkb}} talk 04:33, 9 December 2020 (UTC)
- Support Thomas Kinz (talk) 09:22, 9 December 2020 (UTC)
- Support JASpencer (talk) 16:28, 9 December 2020 (UTC)
- Support Lirazelf (talk) 16:39, 9 December 2020 (UTC)
- Support Emanuele676 (talk) 00:17, 10 December 2020 (UTC)
- Support this fixes a long-term problem Libcub (talk) 18:13, 10 December 2020 (UTC)
- Support If it is to correct links after archiving, the proposal is excellent. WikiFer msg 22:29, 10 December 2020 (UTC)
- Yes, this is exactly what this proposal is about. --Matthiaspaul (talk) 12:53, 13 December 2020 (UTC)
- Support — Bilorv (talk) 00:44, 11 December 2020 (UTC)
- Support James Martindale (talk) 17:53, 11 December 2020 (UTC)
- Support Ahecht (TALK
PAGE) 18:24, 11 December 2020 (UTC) - Support Mahedi Hasan (talk) 11:05, 12 December 2020 (UTC)
- Support MichaelMaggs (talk) 15:00, 12 December 2020 (UTC)
- Support Please make it into Pywikibot core and provide an option in archivebot.py to automatically apply it. Tacsipacsi (talk) 21:51, 14 December 2020 (UTC)
- Support Terra ❤ (talk) 00:04, 15 December 2020 (UTC)
- Support — Draceane talkcontrib. 12:50, 15 December 2020 (UTC)
- Support Shenme (talk) 04:50, 17 December 2020 (UTC)
- Support Kku (talk) 07:51, 17 December 2020 (UTC)
- Support VKG1985 (talk) 17:27, 18 December 2020 (UTC)
- Support Sorou6sh (talk) 10:15, 19 December 2020 (UTC)
- Support Clearly useful! Uanfala (talk) 22:09, 19 December 2020 (UTC)
- Support Julián L. Páez 03:30, 21 December 2020 (UTC)
InternetArchiveBot for Wikidata
- Problem: Dead links are not managed in an automated way in Wikidata
- Who would benefit: Wikidata and all projects using it
- Proposed solution: Adapt InternetArchiveBot to Wikidata and add archival URLs to dead links for URL and external identifiers datatypes.
- More comments:
- Phabricator tickets:
- Proposer: Ayack (talk) 10:29, 26 November 2020 (UTC)
Discussion
- @Ayack: InternetArchiveBot already does add archive links to Reference URL properties on Wikidata (e.g.). So just to clarify, this proposal is to add an 'archive URL' (and date) qualifier to statements of type URL or external identifier? —Sam Wilson 02:54, 27 November 2020 (UTC)
- @Samwilson: Yes, the goal is to manage 'archive URL' for all URL and external identifier properties. Ayack (talk) 09:13, 27 November 2020 (UTC)
- I just left a note at the bot owner's talk page about this. It's possible that he could make this change before the 2021 Wishlist work would have any chance of starting (July 2021). WhatamIdoing (talk) 18:47, 14 December 2020 (UTC)
- @WhatamIdoing: Any response / update? –SJ talk 18:31, 27 October 2021 (UTC)
Voting
- Support IagoQnsi (talk) 18:36, 8 December 2020 (UTC)
- Support Waddie96 (talk) 18:38, 8 December 2020 (UTC)
- Support Owleksandra (talk) 18:46, 8 December 2020 (UTC)
- Support Thryduulf (talk: meta · en.wp · wikidata) 20:07, 8 December 2020 (UTC)
- Support CrystallineLeMonde (talk) 20:21, 8 December 2020 (UTC)
- Support Silver hr (talk) 20:43, 8 December 2020 (UTC)
- Support Sabas88 (talk) 20:51, 8 December 2020 (UTC)
- Support josecurioso ❯❯❯ Tell me! 23:02, 8 December 2020 (UTC)
- Support YFdyh000 (talk) 23:25, 8 December 2020 (UTC)
- Support PianistHere (talk) 01:25, 9 December 2020 (UTC)
- Support BugWarp (talk) 01:34, 9 December 2020 (UTC)
- Support Hanif Al Husaini (talk) 01:51, 9 December 2020 (UTC)
- Support ──post by kenny2wiki Talk Contribs 02:36, 9 December 2020 (UTC)
- Support Pamzeis (talk) 02:52, 9 December 2020 (UTC)
- Support For Wikidata to ever get buy-in from en-WP and other large projects, the two biggest problems it needs to solve are vandalism and referencing. This would be a big step forward regarding the latter. {{u|Sdkb}} talk 04:21, 9 December 2020 (UTC)
- Support —— Eric Liu(留言.百科用戶頁) 04:42, 9 December 2020 (UTC)
- Support Xinbenlv (talk) 04:56, 9 December 2020 (UTC)
- Support Xgeorg (talk) 06:52, 9 December 2020 (UTC)
- Support Omda4wady (talk) 07:25, 9 December 2020 (UTC)
- Support no-brainer Thomas Kinz (talk) 09:25, 9 December 2020 (UTC)
- Support Tmv (talk) 09:55, 9 December 2020 (UTC)
- Support Kpjas (talk) 10:42, 9 December 2020 (UTC)
- Support JAn Dudík (talk) 10:44, 9 December 2020 (UTC)
- Support Lion-hearted85 (talk) 11:26, 9 December 2020 (UTC)
- Support 1Mmarek (talk) 11:34, 9 December 2020 (UTC)
- Support ‐‐1997kB (talk) 13:56, 9 December 2020 (UTC)
- Support Sannita - not just another it.wiki sysop 15:12, 9 December 2020 (UTC)
- Support Pechristener (talk) 17:28, 9 December 2020 (UTC)
- Support Rafael (stanglavine) msg 18:32, 9 December 2020 (UTC)
- Support Cabayi (talk) 20:19, 9 December 2020 (UTC)
- Support TheAmerikaner (talk) 20:27, 9 December 2020 (UTC)
- Support Browk2512 (talk) 21:13, 9 December 2020 (UTC)
- Support John Samuel 21:14, 9 December 2020 (UTC)
- Support Moebeus (talk) 21:48, 9 December 2020 (UTC)
- Support Jh15s (talk) 21:51, 9 December 2020 (UTC)
- Strong support NMaia (talk) 01:23, 10 December 2020 (UTC)
- Support - Darwin Ahoy! 01:41, 10 December 2020 (UTC)
- Support wiki + IA forever Blue Rasberry (talk) 01:50, 10 December 2020 (UTC)
- Support JPxG (talk) 05:43, 10 December 2020 (UTC)
- Support Majash2020 (talk) 05:53, 10 December 2020 (UTC)
- Support ··· 🌸 Rachmat04 · ☕ 06:41, 10 December 2020 (UTC)
- Support Spasimir (talk) 10:16, 10 December 2020 (UTC)
- Support Euro know (talk) 11:02, 10 December 2020 (UTC)
- Support THeK3nger (talk) 11:13, 10 December 2020 (UTC)
- Support β16 - (talk) 11:44, 10 December 2020 (UTC)
- Support Ayack (talk) 16:28, 10 December 2020 (UTC)
- Support Libcub (talk) 18:26, 10 December 2020 (UTC)
- Support Afernand74 (talk) 20:20, 10 December 2020 (UTC)
- Support The proposal is excellent because it avoids dead links on Wikidata. WikiFer msg 23:25, 10 December 2020 (UTC)
- Support Strong support. BoldLuis (talk) 10:58, 11 December 2020 (UTC)
- Support valepert (talk) 12:26, 11 December 2020 (UTC)
- Support Dhx1 (talk) 13:19, 11 December 2020 (UTC)
- Support Izno (talk) 15:29, 11 December 2020 (UTC)
- Support Bencemac (talk) 16:12, 11 December 2020 (UTC)
- Support GiFontenelle (talk) 16:18, 11 December 2020 (UTC)
- Support Ameisenigel (talk) 16:31, 11 December 2020 (UTC)
- Support Watty62 (talk) 16:48, 11 December 2020 (UTC)
- Support czar 17:51, 11 December 2020 (UTC)
- Support DemonDays64 (talk) 18:34, 11 December 2020 (UTC)
- Support Anaxial (talk) 18:47, 11 December 2020 (UTC)
- Support Of course. Robins7 (talk) 21:57, 11 December 2020 (UTC)
- Support Frozenmadness (talk) 23:22, 11 December 2020 (UTC)
- Support big support for this one. Redalert2fan (talk) 00:11, 12 December 2020 (UTC)
- Support Dirac (talk) 00:20, 12 December 2020 (UTC)
- Support --Alaa :)..! 01:10, 12 December 2020 (UTC)
- Support — AfroThundr (u · t · c) 05:08, 12 December 2020 (UTC)
- Support Francois-Pier (talk) 11:52, 12 December 2020 (UTC)
- Support Tom Ja (talk) 12:26, 12 December 2020 (UTC)
- Support --Gaux (talk) 13:37, 12 December 2020 (UTC)
- Support (`・ω・´) (talk) 13:40, 12 December 2020 (UTC)
- Support Conny (talk) 15:41, 12 December 2020 (UTC)
- Support Kew Gardens 613 (talk) 02:43, 13 December 2020 (UTC)
- Support Tgr (talk) 05:49, 13 December 2020 (UTC)
- Support ~ Amory (u • t • c) 19:47, 13 December 2020 (UTC)
- Support Gelli1742 (talk) 20:21, 13 December 2020 (UTC)
- Support In principle I support the idea, but I question if this should be done by a bot or just by an extension so that other users of Wikibase etc can easily make use of the functionality too. ·addshore· talk to me! 12:58, 14 December 2020 (UTC)
- Support Michel Bakni (talk) 13:59, 14 December 2020 (UTC)
- Support Jurbop (talk) 07:22, 15 December 2020 (UTC)
- Support MTheiler (talk) 16:33, 15 December 2020 (UTC)
- Support Anonyme314159 (talk) 18:35, 15 December 2020 (UTC)
- Support Utopes (talk) 19:34, 15 December 2020 (UTC)
- Support SpringProof (talk) 22:34, 15 December 2020 (UTC)
- Support Jstalins (talk) 04:42, 16 December 2020 (UTC)
- Support Nelson Ricardo (talk) 11:21, 16 December 2020 (UTC)
- Support Wolfmartyn (talk) 14:09, 16 December 2020 (UTC)
- Support Stephan Hense (talk) 23:01, 16 December 2020 (UTC)
- Support F. Riedelio (talk) 10:07, 17 December 2020 (UTC)
- Support Gdafs (talk) 15:02, 17 December 2020 (UTC)
- Support Temp3600 (talk) 17:38, 17 December 2020 (UTC)
- Support Base (talk) 19:33, 17 December 2020 (UTC)
- Support VKG1985 (talk) 17:24, 18 December 2020 (UTC)
- Support Hameryko (talk) 13:19, 19 December 2020 (UTC)
- Support HLHJ (talk) 00:16, 20 December 2020 (UTC)
- Support AdaHephais (talk) 05:51, 20 December 2020 (UTC)
- Support Iva (talk) 15:53, 20 December 2020 (UTC)
- Support Powerek38 (talk) 18:39, 20 December 2020 (UTC)
- Support --Teukros (talk) 18:41, 20 December 2020 (UTC)
- Support Juan90264 (talk) 03:06, 21 December 2020 (UTC)
- Support Ahmadtalk 03:22, 21 December 2020 (UTC)
- Support Nicereddy (talk) 04:09, 21 December 2020 (UTC)
- Support Emha (talk) 12:50, 21 December 2020 (UTC)
- Support S8321414 (talk) 14:06, 21 December 2020 (UTC)
- Support Nadzik (talk) 17:22, 21 December 2020 (UTC)
Importing data from IMDb
- Problem: When creating new pages for actors, directors, etc. much of the information is available in a structuring format on their IMDb page but it is time-consuming to transfer manually to Wikipedia.
- Who would benefit: Editors creating, improving, or updating pages that use IMDb for information.
- Proposed solution: A tool that can auto-import IMDb fields (e.g. year, title of movie/show, role, etc.) and a bot that will update articles when there is an addition to their IMDb page.
- More comments:
- Phabricator tickets:
- Proposer: GeneralBelly (talk) 22:23, 24 November 2020 (UTC)
Discussion
- @GeneralBelly: There are already Mix-n-match catalogues for IMDb (for example, for actors; find them all by searching 'imdb' in the catalogue search form), to help with the importing part of this. Is that sufficient? The work then is to integrate this data into Wikipedia articles, the technical functionality for which already exists. —Sam Wilson 03:18, 25 November 2020 (UTC)
- Hi Samwilson, I'm not familiar with Mix-n-match but I had a look at it and couldn't figure out a way to use it. Basically, I was hoping for a tool where I could identify an IMDb entry for an actor, e.g. Michelle Yeoh https://www.imdb.com/name/nm0000706/ and it would give me a table of her work in wiki markup which I could add directly to the article. Is that possible? --GeneralBelly (talk) 16:27, 30 November 2020 (UTC)
- @GeneralBelly: Sounds good. Mix-n-match helps with getting the actors' and movies' details into Wikidata, from where they can be added to Wikipedia articles. This can be done dynamically with Lua in some cases (for individual items) or en masse via a bot such as {{Wikidata list}}, or via wikitext exports. The details can be figured out after voting. —Sam Wilson 04:03, 1 December 2020 (UTC)
- This seems perfectly suited to go through Wikidata. Silver hr (talk) 18:09, 30 November 2020 (UTC)
- How would we avoid copyright issues? Oaktree b (talk) 16:26, 9 December 2020 (UTC)
Voting
- Support Owleksandra (talk) 18:45, 8 December 2020 (UTC)
- Support ThadeusOfNazereth (talk) 19:35, 8 December 2020 (UTC)
- Support A good idea شادي (talk) 22:33, 8 December 2020 (UTC)
- Support UncleMartin (talk) 01:31, 9 December 2020 (UTC)
- Support BugWarp (talk) 01:33, 9 December 2020 (UTC)
- Support Implementing it to go through Wikidata sounds reasonable. Thomas Kinz (talk) 09:24, 9 December 2020 (UTC)
- Support Lirazelf (talk) 16:48, 9 December 2020 (UTC)
- Support XenoF (talk) 18:36, 9 December 2020 (UTC)
- Oppose IMDb is not a reliable source. Cabayi (talk) 20:24, 9 December 2020 (UTC)
- Support Emanuele676 (talk) 00:17, 10 December 2020 (UTC)
- Support - Darwin Ahoy! 01:41, 10 December 2020 (UTC)
- Support - yona B. (D) 07:10, 10 December 2020 (UTC)
- Support Nonahg (talk) 08:47, 10 December 2020 (UTC)
- Support Euro know (talk) 11:03, 10 December 2020 (UTC)
 NeutralI am not sure how much information should be imported from IMDb since it could count as plagiarism. If it is just the dates, the name, etc, then there's very little benefit to getting them from a bot. It takes less than 5 seconds to copy and paste each respective information. MarioSuperstar77 (talk) 11:35, 10 December 2020 (UTC)
NeutralI am not sure how much information should be imported from IMDb since it could count as plagiarism. If it is just the dates, the name, etc, then there's very little benefit to getting them from a bot. It takes less than 5 seconds to copy and paste each respective information. MarioSuperstar77 (talk) 11:35, 10 December 2020 (UTC)- Oppose IMDb is user-edited and should not be automatically imported. — HELLKNOWZ ▎TALK ▎enWiki 22:12, 10 December 2020 (UTC)
- Support IMDB is a database and it is important that you can import and a bot to update entry information. WikiFer msg 23:22, 10 December 2020 (UTC)
- Oppose Absolutely not. IMDB is not a reliable source. KevinL (aka L235 · t) 01:03, 11 December 2020 (UTC)
- Support Not automatically, because after importing in a preview, must be ratified by the user. BoldLuis (talk) 10:42, 11 December 2020 (UTC)
- Oppose IMDB is not a reliable source, see perennial sources for more info. Alexcalamaro (talk) 10:46, 11 December 2020 (UTC)
- Oppose IMDb is a wiki. — Alexis Jazz (talk or ping me) 12:34, 11 December 2020 (UTC)
- Oppose IMDB is not reliable enough to let the information flow automatically into wikipedia. Hkoala (talk) 17:25, 11 December 2020 (UTC)
- Oppose IMDb ist not a reliable source. Anyone can edit it. The contributions there get checked, but you don't need to provide sources for an editting request. --Gereon K. (talk) 17:27, 11 December 2020 (UTC)
- Support IMDB is a wiki, anyone can edit it. Wikipedia is not a wiki, rly? Фред-Продавец звёзд (talk) 19:13, 11 December 2020 (UTC)
- @Фред-Продавец звёзд: Wikipedia is a wiki that requires all statements to be verifiable. On IMDb, nothing is sourced. So you may be able to import some information, but you'll still be spending most of your time hunting down proper references to support this information. By allowing easy import, we would only stimulate users to add unsourced information to biographies. — Alexis Jazz (talk or ping me) 20:41, 12 December 2020 (UTC)
 Strong oppose -- Importing user generated content is never a good idea. See also en:WP:UGC. Wutsje (talk) 20:17, 11 December 2020 (UTC)
Strong oppose -- Importing user generated content is never a good idea. See also en:WP:UGC. Wutsje (talk) 20:17, 11 December 2020 (UTC)- Oppose As other opposes have noted, IMDB is user generated content. ONUnicorn (talk) 21:25, 11 December 2020 (UTC)
- Oppose Francois-Pier (talk) 11:49, 12 December 2020 (UTC)
- Oppose IMDb is a user-edited site. We don't accept Wikipedia as a reliable source, so why would IMDb be any different?--Sudonet (talk) 18:25, 12 December 2020 (UTC)
- Oppose --Encycloon (talk) 17:34, 13 December 2020 (UTC)
- Support Lomrjyo (talk) 19:21, 14 December 2020 (UTC)
- Support Ææqwerty (talk) 08:54, 16 December 2020 (UTC)
- Support Support and suggest the same for other areas, such as transfermarkt for football players. Wolfmartyn (talk) 14:13, 16 December 2020 (UTC)
- Support Risk Engineer (talk) 15:51, 17 December 2020 (UTC)
- Oppose IMDB should not be relied as the primary source.--Temp3600 (talk) 17:41, 17 December 2020 (UTC)
- Support Unclemoo92 (talk) 20:40, 17 December 2020 (UTC)
- Support if information can be backed up with a WP:RS, as IMDb cannot be the sole source to a claim. DarkGlow (talk) 21:32, 17 December 2020 (UTC)
- Support Make works more easy. Sorou6sh (talk) 10:08, 19 December 2020 (UTC)
- Strong oppose IMDB is not a reliable source and should not be used as a refence in any case. WikiAviator (talk) 12:40, 20 December 2020 (UTC)
- Support Great idea! Dolotta (talk) 16:24, 20 December 2020 (UTC)
- Oppose per L235 and Oaktree b —2d37 (talk) 10:49, 21 December 2020 (UTC)
- Support S8321414 (talk) 14:06, 21 December 2020 (UTC)
- Oppose IMDb is not a reliable source. --Thibaut (talk) 16:56, 21 December 2020 (UTC)
ListeriaBot to add alias meta-column
- Problem : Wikidata Query and ListeriBot currently only knows "label", and "description" as standard item columns; "alias" is not recognised yet as a valid item header variable.
- Who would benefit: Everyone that automatically generates (Wikipedia) tables based on a Wikidata Query.
- Proposed solution: Add a pseudo-column "alias" that is automatically and transparently available for any individual query.
- More comments: Currently this can be simulated by explicitly adding a SPARQL variable
?aliasas:
OPTIONAL {
?item skos:altLabel ?alias.
FILTER((LANG(?alias)) = "nl")
}
This makes the Wikidata Query unnecessary complex, and leads to redundant user code in all Wikidata/LysteriaBot queries.
Actually, instead of enhancing Listeria, this alias could better be made available in Wikidata Query; just like itemLabel and itemDescription are a variable, itemAlias could be created as another default variable.
- Phabricator tickets:
- Proposer: Geert Van Pamel (WMBE) (talk) 11:10, 20 November 2020 (UTC)
Discussion
- You mean "ListeriaBot", right? --Matěj Suchánek (talk) 17:10, 20 November 2020 (UTC)
- Yes, I do. Geert Van Pamel (WMBE) (talk) 18:00, 20 November 2020 (UTC)
- renamed —TheDJ (talk • contribs) 12:30, 21 November 2020 (UTC)
- Yes, I do. Geert Van Pamel (WMBE) (talk) 18:00, 20 November 2020 (UTC)
- @Geertivp: Have you tried to file a request with the author of the tool, Magnus Manske https://github.com/magnusmanske/listeria_rs/issues ? —TheDJ (talk • contribs) 12:28, 21 November 2020 (UTC)
- Good idea. I did now. See https://github.com/magnusmanske/listeria_rs/issues/24 Geert Van Pamel (WMBE) (talk) 12:59, 21 November 2020 (UTC)
Done. --Magnus Manske (talk) 15:46, 9 December 2020 (UTC)
Voting
- Support Simpler coding Geert Van Pamel (WMBE) (talk) 19:01, 8 December 2020 (UTC)
- Support Silver hr (talk) 20:42, 8 December 2020 (UTC)
- Support Paul Hermans (talk) 08:22, 9 December 2020 (UTC)
- Support Libcub (talk) 18:14, 10 December 2020 (UTC)
- Support Help in creating tables by Wikidata Query. WikiFer msg 23:37, 10 December 2020 (UTC)
- Support big support হানিফ আলী (talk) 10:24, 11 December 2020 (UTC)
- Support BoldLuis (talk) 10:37, 11 December 2020 (UTC)
- Support Strainu (talk) 09:42, 12 December 2020 (UTC)
- Support Search gets optimized too. Conny (talk) 15:40, 12 December 2020 (UTC)
- Support Nashona (talk) 03:03, 18 December 2020 (UTC)
- Support VKG1985 (talk) 17:17, 18 December 2020 (UTC)
- Support Juan90264 (talk) 07:51, 21 December 2020 (UTC)
Revive the death anomalies project
- Problem: When people die we don't always notice and update all language versions of the article on them
- Who would benefit: All Wikipedias. When this used to run lots of articles were improved.
- Proposed solution: Revive the death anomalies project. Until the bot operator retired, we had a bot that produced regular lists for 11 language versions of Wikipedia of people who were alive on their version of Wikipedia, but dead according to another language. People would then check sources, usually mark the person as dead in their language, sometimes as not dead in the other language.
- More comments:
- Phabricator tickets:
- Proposer: WereSpielChequers (talk) 22:20, 29 November 2020 (UTC)
Discussion
- It seems like this could be done through Wikidata, where the datum about a person being alive or dead could be centrally stored and then displayed in any Wikipedia. Silver hr (talk) 18:04, 30 November 2020 (UTC)
- Yes, it is technically possible to do this, it just needs programing resource. WereSpielChequers (talk) 06:56, 2 December 2020 (UTC)
- Wikidata is already the necessary ready-4-use no-code solution. Sagivrash (talk) 18:50, 8 December 2020 (UTC)
- Here is the PetScan query for German Wikipedia, all biographical articles without a death date category but where the Wikidata item has a death date. Some false positives, can be refined further. Categories have to be adjusted for other language editions. --Magnus Manske (talk) 15:53, 9 December 2020 (UTC)
- This can be done using Wikidata. Some Wikipedias event have it in the main page. -Theklan (talk) 17:45, 11 December 2020 (UTC)
- Related: A while ago I noted that a featured article was badly outdated. I updated with more recent scholarship, but there are, as I recall, literally dozens of featured articles on the same subject in other languages. I'd like a way to push a notification that those articles may not be of featured quality anymore, especially if they have no/few references published in the past decade or two. A cross-language way to tag topics as "significant new info in reliable sources published during [timespan]", cited, would work. I expect this problem will become more common as Wikipedia matures. HLHJ (talk) 00:08, 20 December 2020 (UTC)
- German Wikipedia is observing mismatches in liveliness at Wikidata, but our investigators will check sources for reliability. A hoax can be made easily on Wikidata, even with fake sources. We will not display automatically what anybody is editing at Wikidata. Wikidata changes without good citation are pointless. If we get a hint that someone might have died we will look for a proof, change German Wikipedia or revert Wikidata. --PerfektesChaos (talk) 13:15, 18 March 2021 (UTC)
Voting
- Support Waddie96 (talk) 18:35, 8 December 2020 (UTC)
- Support Shoeper (talk) 18:43, 8 December 2020 (UTC)
- Support ThadeusOfNazereth (talk) 19:34, 8 December 2020 (UTC)
- Support GiovanniPen (talk) 19:52, 8 December 2020 (UTC)
- Support Xinbenlv (talk) 04:56, 9 December 2020 (UTC)
- Support Thomas Kinz (talk) 09:32, 9 December 2020 (UTC)
- Support This was invaluable for BLP checking when the list was updated Lugnuts (talk) 12:26, 9 December 2020 (UTC)
- Support TheAmerikaner (talk) 20:28, 9 December 2020 (UTC)
- Support Libcub (talk) 18:26, 10 December 2020 (UTC)
- Support Benimation (talk) 22:35, 10 December 2020 (UTC)
- Support It helps volunteers to check whether such a biographer has died or not. WikiFer msg 23:00, 10 December 2020 (UTC)
- Support Using Wikidata. BoldLuis (talk) 10:52, 11 December 2020 (UTC)
- Support With Wikidata! GiFontenelle (talk) 16:30, 11 December 2020 (UTC)
- Support Krinkle (talk) 20:17, 11 December 2020 (UTC)
- Support Good idea AMX (talk) 10:42, 13 December 2020 (UTC)
- Support Jthekid15 (talk) 09:52, 15 December 2020 (UTC)
- Support I support everything for this year. Reference 8 (talk) 20:07, 15 December 2020 (UTC)
- Support SpringProof (talk) 22:35, 15 December 2020 (UTC)
- Support Dr-Taher (talk) 07:33, 16 December 2020 (UTC)
- Support Love the pun of the title. Wolfmartyn (talk) 14:09, 16 December 2020 (UTC)
- Support Temp3600 (talk) 17:41, 17 December 2020 (UTC)
- Support Would be nice to have. Though this is one of those things where I am hoping that it would be not community tech but independent bot operators who would focus on this Base (talk) 19:58, 17 December 2020 (UTC)
- Support Owleksandra (talk) 19:59, 17 December 2020 (UTC)
- Support Nashona (talk) 03:00, 18 December 2020 (UTC)
- Support Sure. Easy to do and useful. HLHJ (talk) 00:11, 20 December 2020 (UTC)
- Support Kelvin (talk) 09:26, 21 December 2020 (UTC)
- Support David1010 (talk) 11:59, 21 December 2020 (UTC)
Bibliographic bot for Wikidata
- Problem: Many references on Wikidata only consist of an URL (P854).
- Who would benefit: Wikidata and all projects using its data
- Proposed solution: Based on reference URL, retrieve (with a bot?) related information (title, language, publication date, author, page, ISBN/ISSN, etc.) and add them to the reference. Data to be added will depend on the source type (book, article, website, etc.).
- More comments:
- Phabricator tickets: task T285498
- Proposer: Ayack (talk) 18:01, 27 November 2020 (UTC)
Discussion
- I think citoid for Wikidata could help here (it's being worked on if I am not mistaken). --Matěj Suchánek (talk) 09:21, 30 November 2020 (UTC)
- So, like an automatic reFill? --Count Count (talk) 19:35, 8 December 2020 (UTC)
- This brings back to mind the prototype wikidata:User:Aude/citoid.js (which as far as I know has not been working for ages, but used to work very well indeed). Jean-Fred (talk) 15:14, 21 December 2020 (UTC)
Voting
- Support Marchitelli (talk) 18:29, 8 December 2020 (UTC)
- Support Waddie96 (talk) 18:35, 8 December 2020 (UTC)
- Support Shoeper (talk) 18:44, 8 December 2020 (UTC)
- Support Sebastian Wallroth (talk) 18:58, 8 December 2020 (UTC)
- Support Movses (talk) 18:59, 8 December 2020 (UTC)
- Support --NGC 54 (talk / contribs) 19:20, 8 December 2020 (UTC)
- Support ThadeusOfNazereth (talk) 19:35, 8 December 2020 (UTC)
- Support CrystallineLeMonde (talk) 20:19, 8 December 2020 (UTC)
- Support Articute (talk) 20:26, 8 December 2020 (UTC)
- Support Silver hr (talk) 20:41, 8 December 2020 (UTC)
- Support Ssstela (talk) 21:16, 8 December 2020 (UTC)
- Support Luis Fernández García (talk) 21:46, 8 December 2020 (UTC)
- Support Iniquity (talk) 23:47, 8 December 2020 (UTC)
- Support Abductive (talk) 00:03, 9 December 2020 (UTC)
- Support BugWarp (talk) 01:35, 9 December 2020 (UTC)
- Support Hanif Al Husaini (talk) 01:52, 9 December 2020 (UTC)
- Support Shizhao (talk) 02:49, 9 December 2020 (UTC)
- Support For Wikidata to ever get buy-in from en-WP and other large projects, the two biggest problems it needs to solve are vandalism and referencing. This would be a big step forward regarding the latter. {{u|Sdkb}} talk 04:19, 9 December 2020 (UTC)
- Support --Till.niermann (talk) 06:33, 9 December 2020 (UTC)
- Support Xgeorg (talk) 06:51, 9 December 2020 (UTC)
- Support Cherryblossom000 (talk) 07:17, 9 December 2020 (UTC)
- Support Omda4wady (talk) 07:23, 9 December 2020 (UTC)
- Support ChrisHodgesUK (talk) 09:02, 9 December 2020 (UTC)
- Support Samwalton9 (talk) 09:34, 9 December 2020 (UTC)
- Support JAn Dudík (talk) 10:46, 9 December 2020 (UTC)
- Support Kpjas (talk) 10:46, 9 December 2020 (UTC)
- Support Pru.mitchell (talk) 13:02, 9 December 2020 (UTC)
- Support ‐‐1997kB (talk) 13:56, 9 December 2020 (UTC)
- Support — Rhododendrites talk \\ 14:29, 9 December 2020 (UTC)
- Support Oaktree b (talk) 16:27, 9 December 2020 (UTC)
- Support Lirazelf (talk) 16:49, 9 December 2020 (UTC)
- Support Tylwyth Eldar (talk) 18:23, 9 December 2020 (UTC)
 Weak support it certainly would save me a lot of stress, but it's also important for editors to themselves be accountable. Tyrekecorrea (talk) 19:52, 9 December 2020 (UTC)
Weak support it certainly would save me a lot of stress, but it's also important for editors to themselves be accountable. Tyrekecorrea (talk) 19:52, 9 December 2020 (UTC)- Support TheAmerikaner (talk) 20:25, 9 December 2020 (UTC)
- Oppose This doesn't need a MediaWiki developer, a bot could do this, which could be done by the community. The more fundamental problem is that there are a lot of statements on Wikidata that don't even have a URL providing a reference. Thanks. Mike Peel (talk) 21:02, 9 December 2020 (UTC)
- Support NMaia (talk) 23:56, 9 December 2020 (UTC)
- Support Yes, please! - Darwin Ahoy! 01:42, 10 December 2020 (UTC)
- Support - yona B. (D) 07:12, 10 December 2020 (UTC)
- Support Nonahg (talk) 08:45, 10 December 2020 (UTC)
- Support Possibly (talk) 08:57, 10 December 2020 (UTC)
- Support Spasimir (talk) 10:14, 10 December 2020 (UTC)
- Support Ayack (talk) 16:28, 10 December 2020 (UTC)
- Support Libcub (talk) 18:24, 10 December 2020 (UTC)
- Support. Meiræ 18:48, 10 December 2020 (UTC)
- Support It brings more verifiability to Wikidata and all its projects that depend on it. WikiFer msg 22:44, 10 December 2020 (UTC)
- Support Should then be operational in different language Wikipedia versions. --Furfur ⁂ Discussion 03:41, 11 December 2020 (UTC)
- Support Ghart27 (talk) 04:06, 11 December 2020 (UTC)
- Support Some1 (talk) 05:25, 11 December 2020 (UTC)
- Support eranroz (talk) 10:23, 11 December 2020 (UTC)
- Support Import Citoid from Wikipedia. It would interestig to create a bot importer. BoldLuis (talk) 10:58, 11 December 2020 (UTC)
- Support Paucabot (talk) 12:28, 11 December 2020 (UTC)
- Support Dhx1 (talk) 13:18, 11 December 2020 (UTC)
- Support Izno (talk) 15:27, 11 December 2020 (UTC)
- Support GiFontenelle (talk) 16:07, 11 December 2020 (UTC)
- Support Bencemac (talk) 16:12, 11 December 2020 (UTC)
- Support Szalax (talk) 16:35, 11 December 2020 (UTC)
- Support Watty62 (talk) 16:45, 11 December 2020 (UTC)
- Support Theklan (talk) 17:37, 11 December 2020 (UTC)
- Support --Teukros (talk) 17:58, 11 December 2020 (UTC)
- Support Krinkle (talk) 20:18, 11 December 2020 (UTC)
- Support Quebec99 (talk) 21:03, 11 December 2020 (UTC)
- Support —Michael Z. 2020-12-11 23:47 z 23:47, 11 December 2020 (UTC)
- Support Redalert2fan (talk) 00:09, 12 December 2020 (UTC)
- Support --Acer11 (talk) 02:43, 12 December 2020 (UTC)
- Support — AfroThundr (u · t · c) 05:08, 12 December 2020 (UTC)
- Support ~Cybularny Speak? 11:14, 12 December 2020 (UTC)
- Support Francois-Pier (talk) 11:55, 12 December 2020 (UTC)
- Support Tom Ja (talk) 12:27, 12 December 2020 (UTC)
- Support Geert Van Pamel (WMBE) (talk) 13:35, 12 December 2020 (UTC)
- Support Yes :) . Conny (talk) 15:42, 12 December 2020 (UTC)
- Support Mike Linksvayer (talk) 19:14, 12 December 2020 (UTC)
- Support TheLatentOne (talk) 19:43, 12 December 2020 (UTC)
- Support Nikkimaria (talk) 17:50, 13 December 2020 (UTC)
- Support Yes. This. Papuass (talk) 21:21, 14 December 2020 (UTC)
- Support MTheiler (talk) 16:36, 15 December 2020 (UTC)
- Support Hlambert63 (talk) 18:00, 15 December 2020 (UTC)
- Support Anonyme314159 (talk) 18:18, 15 December 2020 (UTC)
- Support Utopes (talk) 19:33, 15 December 2020 (UTC)
- Support SpringProof (talk) 22:39, 15 December 2020 (UTC)
- Support that would be nice, I'm often guilty of URL only references. Wolfmartyn (talk) 14:07, 16 December 2020 (UTC)
- Support Dankowski (talk) 20:24, 16 December 2020 (UTC)
- Support Joalbertine (talk) 14:31, 17 December 2020 (UTC)
- Support Gdafs (talk) 15:03, 17 December 2020 (UTC)
- Support Shinkolobwe (talk) 16:21, 17 December 2020 (UTC)
- Support Base (talk) 19:28, 17 December 2020 (UTC)
- Support Owleksandra (talk) 19:28, 17 December 2020 (UTC)
- Support Gikü (talk) 22:56, 17 December 2020 (UTC)
- Support Nashona (talk) 02:58, 18 December 2020 (UTC)
- Support Robins7 (talk) 16:52, 18 December 2020 (UTC)
- Support AdaHephais (talk) 05:48, 20 December 2020 (UTC)
- Support Nicereddy (talk) 04:11, 21 December 2020 (UTC)
- Support :JarrahTree (talk) 08:52, 21 December 2020 (UTC)
- Support David1010 (talk) 12:00, 21 December 2020 (UTC)
- Support Emha (talk) 12:50, 21 December 2020 (UTC)
- Support S8321414 (talk) 14:06, 21 December 2020 (UTC)