Research:Identification of Unsourced Statements
via arXiv Redi, M., Fetahu, B., Morgan, J., & Taraborelli, D. (2019, May). Citation Needed: A Taxonomy and Algorithmic Assessment of Wikipedia's Verifiability. In The World Wide Web Conference (pp. 1567-1578). ACM.

This page documents a research project in progress.
Information may be incomplete and change as the project progresses.
Please contact the project lead before formally citing or reusing results from this page.
To guarantee reliability, Wikipedia's Verifiability policy requires inline citations for any material challenged or likely to be challenged, and for all quotations, anywhere in the article space. While already around 300K statements [4] have been identified as unsourced, we might be missing many more!
This project aims to help the community discover potentially unsourced statements, i.e. statements that need an inline citation to a reliable source, using a machine assisted framework.
Approach
editWe will flag statements that might need the [citation needed] tag. This recommendation will be based on a classifier that can identify whether a statement needs a reference or not. The classifier will encode general rules on referencing and verifiability, which will come from existing guidelines [1][2] or new observational studies we will put in place.
More specifically, we propose to design a supervised learning classifier that, given examples of statements with citations (or needing citations), and examples of statements where citations are not required, learns how to flag statements with the [citation needed] Template.
Refining the Scope
editThe space of possibilties for this project might be too wide. We want to refine the scope of this project so that we address issues which are important across wikis.
Requirements
editThe project has to tackle a category of articles:
- Which are Sensitive: a lot of attention is given to the quality of these articles.
- Whose editing rules are shared by multplie language communities.
Proposed Solution
editOne of the main category of articles fullfilling the 2 requirements is the Biographies of Living People Category. Not only this category is present in 100+ languages (with 850K pages in English, 150k in Spanish, 175k in Italian, 80K in Portoguese, 80K in Chinese) but also, it is considered a sensitive category by all these projects. There is a resolution of the foundation giving directions on how to write biographies of living people. This resolution is written on many languages, and many language-specific guidelines point to it. It says:
The Wikimedia Foundation Board of Trustees urges the global Wikimedia community to uphold and strengthen our commitment to high-quality, accurate information, by: * Ensuring that projects in all languages that describe living people have policies in place calling for special attention to the principles of neutrality and verifiability in those articles; * Taking human dignity and respect for personal privacy into account when adding or removing information, especially in articles of ephemeral or marginal interest; * Investigating new technical mechanisms to assess edits, particularly when they affect living people, and to better enable readers to report problems; * Treating any person who has a complaint about how they are described in our projects with patience, kindness, and respect, and encouraging others to do the same.
Supporting Material for the Project
editHere some pointers to interesting places where we can find supporting material/data for our project. A general page to watch is the WikiProject on BLP. This page contains pointers to guidelines, data, contests, and users we might want to contact to get further information.
Generalization and Proposed Goals
editAfter investigating solutions focused on BLP only, we decided to broaden the scope and use mixed methods to:
- Citation Reason Taxonomy: understand systematically, what are the reason behind editors choose to add a citation (taking into account the importance of the BLP policies), and create a taxonomy of these reasons.
- Citation Need Model: design a machine learning framework to detect statements needing citations.
- Citation Reason Model: design a second framework to detect the reason why statements need citations.
Collecting Statements Data
editWe created three distinct datasets to train models predicting if a statement requires a citation or not. Each dataset consists of:
- Positives: statements with an inline citation.
- Negatives: statements where an inline citation is not needed. Although everything should be cited, we should avoid citation overkill
Positive examples (statements needing citation) are potentially easy to discover - they are already referenced or flagged as unsourced with the [citation needed] tag. Negative examples (statements not requiring citation) are much harder to find. One can do it automatically by finding statements where the [citation needed] tag has been removed. However, these are very few. We could also consider as negatives statements that do not have an inline citation. But can we rely on this data? We need to make sure that the article we source data from are of high quality.
Core Data: Featured Articles
editWe collect sample data from the best articles in Wikipedia. From the set of 5,260 Featured Articles articles we randomly sampled 10,000 positive instances, and equal number of negative instances. These are statements that are very likely to be well cited. To be able to test some of our models on biographies of living people, we use Wikidata to isolate the Featured Articles that are Biographies.
Multilingual Data
editWe will expand the models trained for English Wikipedia to other languages. Since most of the Wikipedia language editions agree on the resolution for sourcing and editing Biographies of Living People, we could potentially annotate sentences and build models on as many languages as we like. Due to large data availability, for this experiment we might want to focus on the major languages:
- English: Wikipedia:Featured_articles
- French: Bons_contenus Article_de_qualité
- Italian: Voci_in_vetrina_su_it Voci_di_qualità_su_it
Validation Data: Lower Quality Articles
editTo test the effectiveness and generalizability of the data trained on high-quality articles, we also sample data from lower quality Wikipedia articles.
- Low Quality (citation needed) – LQN. In this dataset, we sample for statements from the 26,140 articles where at least one of the statements contains a citation needed tag. The positive instances consist solely of statements with citation needed tags.
- Random – RND. In the random dataset, we sample for a total of 20,0000 positive and negative instances from all Wikipedia articles.
Data Format
editWe split each article into paragraphs and sentences, then format a file for each language as follows:
<Wikidata ID> <Article Title> <Sec Title> <Start> <Offset> <Sentence> <Paragraph> <Reference|N\A (if not cited)>
Sample line:
7330495 Richie Farmer Post-playing career 34048 203 He was one of 88 inaugural members of the University of Kentucky Athletics Hall of Fame in 2005 and one of 16 inaugural members of the Kentucky High School Basketball Hall of Fame in 2012.{{207}}{{208}} Farmer was inducted into the KHSAA Hall of Fame in 1998 and the Kentucky Athletic Hall of Fame in 2002.\{\{205}}{{206}} He was one of 88 inaugural members of the University of Kentucky Athletics Hall of Fame in 2005 and one of 16 inaugural members of the Kentucky High School Basketball Hall of Fame in 2012.{{207}}{{208}} \"The Unforgettables\" were honored on a limited edition collector's bottle of [[Maker's Mark]] [[Bourbon whiskey|bourbon]] in 2007.{{209}} {newspaper=lexington herald-leader, date=march 31, 2007, page=b3</ref>, title='unforgettables' made their mark, type=news, cite news} {newspaper=lexington herald-leader, date=july 11, 2012, page=b5</ref>, title=first class for high school hall of fame – 16 ky. stars to be inducted in elizabethtown on saturday, type=news, <ref name=kyhsbbhof>cite news}
Data Analysis
editCompared to the average featured articles, the percentage of statements having citations in biographies is much higher!
.png)
.png)
Collecting Annotations on Citation Reasons: WikiLabels
editTo generate a taxonomy of reasons why editors add citations to sentences in Wikipedia, we design a qualitative experiment involving the communities of Italian, French, and English Wikipedians.
Manual Annotation: Experimental Design
editWe ask editors of the 3 language communities to complete a task on the WikiLabels platform. Given a set of candidate statements, we ask WikiLabels editors to look at each statement and tag it as needing or not needing citation, and why. We conducted 2 different Wiki Labels pilots:
- Collecting free-text reasons for citation needed tag: Research:Identification_of_Unsourced_Statements/Citation_Reason_Pilot. This is the first experiment, where we gather opinions from editors regarding the reasons why sentences need citations. Once we have a good taxonomy of reasons, we can use them to perform the second pilot.
- Collecting reason annotations for sourced/unsourced statements: Research:Identification_of_Unsourced_Statements/Labeling_Pilot
Interface Example
edit- A scrollable frame visualizes an article without citations [reasoning: it simulates the worst-case, most difficult scenario for editors]
- The article is anchored on <Sec Title>;
- The block of text between <Start> and <Offset> is highlighted. The highlighted sentence is the statement to be annotated.
- Editors are invited to make a decision on whether the statement needs citation or not [TODO: exact text].
- [Pilot 1] Through a free-text form, editors are also invited to provide a reason for their choice.
- [Pilot 2] Through a dropdown menu, editors are also invited to provide a reason for their choice from a pre-defined set.
- Both choice and reason are recorded by WikiLabels


Guidelines and templates to watch for data collection (and modeling)
edit- Best Practices mined from Wikipedia citation guidelines: https://docs.google.com/a/wikimedia.org/spreadsheets/d/1nUc8WmtU8F97vcmNv9LnqNSmOiK2UU9AOAl2JBdRFBs/edit?usp=sharing
- Careful With The {cn} tag! Patterns of typical reasons why editors add the [citation needed] tag to a statement here. Main message is - not all the times the flag is added because of content, but often also because of broken link or not reliable source.
- Some BLP articles were marked as 'A CLASS' by the members of the Wiki Project BLP. We might want to learn (and possibly extract negatives) from these featured articles. Guidelines of this initiative can help with this as well.
- When completely missing citations, biographies of living people are marked as Unreferenced. When partially missing citations, they can be found in the BLP_articles_lacking_sources category. This might be a good set to focus on: we can mark the individual sentences in these articles that actually need a source. Some of these ULBP were actually 'rescued' by the volunteers. We can learn something from this rescuing process, and extract positive/negative candidates from rescued BLPs.
Citation Reason Taxonomy
editThe taxonomy of reasons why sentences need citations is shown below.
Reasons for adding a citation
editPlease choose the reason that is most applicable.
- The statement appears to be a direct quotation or close paraphrase of a source
- The statement contains statistics or data
- The statement contains surprising or potentially controversial claims - e.g. a conspiracy theory (see Wikipedia:List_of_controversial_issues for examples)
- The statement contains claims about a person's subjective opinion or idea about something
- The statement contains claims about a person's private life - e.g. date of birth, relationship status.
- The statement contains technical or scientific claims
- The statement contains claims about general or historical facts that are not common knowledge
- The statement requires a citation for reasons not listed above (please describe your reason in a sentence or two)
Reasons for not adding a citation
editPlease choose the reason that is most applicable.
- The statement only contains common knowledge - e.g. established historical or observable facts
- The statement is in the lead section and its content is referenced elsewhere in the article
- The statement is about a plot or character of a book/movie that is the main subject of the article
- The statement only contains claims that have been referenced elsewhere in the paragraph or article
- The statement does not require a citation for reasons not listed above (please describe your reason in a sentence or two)
I can't decide whether this statement needs a citation
editGeneral 'other' category to help discourage random guessing.
Citation Need Modeling
editAfter a feasibility analysis designed to analyze the separability of positive and negative samples in the feature space, we design a deep-learning based framework for this task, and provide a baseline for performance comparison.
Baseline: Feature Extraction + Learning
editFollowing the guidelines for inline citation need, we implement a set of features that can help model relevant aspects of the sentences. Features are based on both Natural Language Processing (multilingual) and structural information. The feature list and motivations can be found here.
Main Section Feature
editThis is a boolean feature equal to 1 if the sentence lies in the article's main section.
Multilingual Word Vectors
editTo get an idea of both the overall content and the style, we compute 300-dimensional language-specific fasttext vectors, taking the dictionaries from this publicly available repository. We then align each non-English language vector to English using alignment matrices. This allows us to have a feature vector from the same space for any language. See full code here.
Words to Watch
editAmong the features implemented, we designed a specific feature to detect the distance from the sentence to the set of Wikipedia's Words to Watch, namely words indicating ambiguous sentences or assumptions/rumors, are available in many languages. To do so, we proceed as follows:
- We identify from the Words to Watch a set of 52 words to watch (see Research:Identification_of_Unsourced_Statements/Word_to_Watch for more details).
- We translate them to other languages by taking the nearest neighbor based on multilingual fastext vectors (62% of matches on Italian translations - see this experiment)
- We compute, for each sentence, the average distance to each word to watch, using fasttext vectors, and store the resulting distance into a 52-d feature vector, code here
Dictionary-based features
editWe design features based on lexical dictionaries, consisting mostly of verbs, constructed for specific tasks:
- report verbs consist of verbs that are used in sentences when a citation is attributed, furthermore these provide also the stance of the person writing the statement w.r.t the cited information. (Recanesens et al., ACL 2013)
- assertive verbs consist of verbs which can weaken or strengthen the believability of a statement. (Hooper. 1975, Syntax and Semantics 1975)
- factive verbs consists of verbs which, when used, provide assurances regarding the truth of a statement. (Hooper 1975, Syntax and Semantics, 1975)
- hedges are words that are used in cases when one tries to weaken the tone in a statement. The word itself can belong to different parts of speech, e.g. (adverb, adjective). (Hyland, Continuum, 2005)
- implicative verbs when used in sentences imply the truth of a given action. (Karttunen, Language 1971)
To construct features based on the above dictionaries, we use the same approach used for the Word to Watch features.
Supervised Learning
editWe use the above features as input for a Random Forest classifier. We define the parameters maximum depth and the number of trees using grid-search on cross-validation.
Deep Learning Framework
editWe use Recurrent Neural Networks with GRU cells to model citation need. We use the attention mechanism to allow the network to focus on specific words, and to learn about what the network is looking at when modeling this space. We use as input to the network the sequence of words in the sentence to be labeled. We also add information about the section where the sentence is placed. For details about the implementation, please refer to our academic paper published at the Web Conference 2019
Results
editThe proposed RNN models outperform the featured-based baselines by a large margin. We observe that adding attention information to a traditional RNN with GRU cells boosts performances by 3-5% Moreover, it is evident that the model is able to capture patterns similar to those of human annotators (e.g. “claimed” in the case of opinion.)


Citation Reason Models
editTo perform the Citation Reason task, we build upon the pre-trained model we modify the RNN model by replacing the dense layer such that we can accommodate all the eight citation reason classes, and use a softmax function for classification. To train the model, we use data labeled by crowdworkers. We collect annotations on 4,000 "positive" sentences regarding the reason why sentences need citations.
Results show that the model is able to correctly categorize sentences in citation reason classes for which we have more labeled data (e.g. "historical")

Potential Applications
edit- Smart Citation Hunt: an enhanced version of the Citation Hunt framework, where sentences to be sourced are automatically extracted using our classifier. An additional button helps to correct machine errors, suggesting that the sentence visualized does not need a citation.
- Smart Editing: A real-time citation needed recommender that classifies sentences as needing citation or not. The classifier detects the end of a sentence while the editor is typing and classifies the new statement on-the-fly.
- Citation Needed Hunt: an API (stand-alone tool) taking as input a sentence and giving as output a citation needed recommendation, together with a confidence score.
-
 Smart Citation Hunt Interface
Smart Citation Hunt Interface -
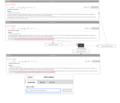 Smart Editing Interface
Smart Editing Interface -
 Citation Needed Hunt Interface
Citation Needed Hunt Interface



Online Evaluation
editWe aim to work in close contact with the Citation Hunt developers and the Wikipedia Library communities. We will pilot a set of a recommendations, powered by the new citation context dataset, to evaluate if our classifiers can help support community efforts to address the problem of unsourced statements.
Timeline
editThis project started as a pilot in October 2017 and will continue until we have an assessment of the performance and suitability of the proposed modeling strategy to support volunteer contributors.
Links
editRepository
editGithub repository with data and code: https://github.com/mirrys/uncited-statement-detection
Pilot experiments with WikiLabels:
edit- Collecting reasons for citation needed tag: Research:Identification_of_Unsourced_Statements/Citation_Reason_Pilot
- Collecting annotations for sourced/unsourced statements: Research:Identification_of_Unsourced_Statements/Labeling_Pilot
- Sign up to the labeling pilot:Sign-up
Guidelines and templates to watch for data collection (and modeling)
edit- Best Practices mined from Wikipedia citation guidelines: https://docs.google.com/a/wikimedia.org/spreadsheets/d/1nUc8WmtU8F97vcmNv9LnqNSmOiK2UU9AOAl2JBdRFBs/edit?usp=sharing
- Patterns of typical reasons why editors add the [citation needed] tag to a statement Research:Identification_of_Unsourced_Statements/Citation_Needed_Reason_Analysis.
Data
edit- Dataset of positive sentences labeled with the reason why they need citations: https://figshare.com/articles/Citation_Reason_Dataset/7756226
References
editSee also
edit- The role of citations in how readers evaluate Wikipedia articles
- Towards modeling citation quality
- Characterizing Wikipedia citation usage
- Citation practices in Wikipedia
- Citation Detective tool
Subpages of this page
editPages with the prefix 'Identification of Unsourced Statements' in the 'Research' and 'Research talk' namespaces:
Research:
- Identification of Unsourced Statements
- Identification of Unsourced Statements/API
- Identification of Unsourced Statements/API design research
- Identification of Unsourced Statements/Citation Needed Reason Analysis
- Identification of Unsourced Statements/Citation Reason Pilot
- Identification of Unsourced Statements/Citation Reason Pilot/FR
- Identification of Unsourced Statements/Citation Reason Pilot/IT
- Identification of Unsourced Statements/Citation Reason Pilot/Initial Results
- Identification of Unsourced Statements/Citation Reason Pilot/Sign Up
- Identification of Unsourced Statements/Citation Reason Pilot/Sign Up/FR
- Identification of Unsourced Statements/Citation Reason Pilot/Sign Up/IT
- Identification of Unsourced Statements/Feasibility Analysis
- Identification of Unsourced Statements/Labeling Pilot
- Identification of Unsourced Statements/Labeling Pilot/FR
- Identification of Unsourced Statements/Labeling Pilot/IT
- Identification of Unsourced Statements/Labeling Pilot/Results
- Identification of Unsourced Statements/Labeling Pilot/Sign Up
- Identification of Unsourced Statements/Labeling Pilot/Sign Up/FR
- Identification of Unsourced Statements/Labeling Pilot/Sign Up/IT
- Identification of Unsourced Statements/WikiLabels: How-to
- Identification of Unsourced Statements/Word to Watch