Research:Newsletter/2012/July

Vol: 2 • Issue: 7 • July 2012 [contribute] [archives]
Conflict dynamics, collaboration and emotions; digitization vs. copyright; WikiProject field notes; quality of medical articles; role of readers; Best Wiki Paper Award
With contributions by: Daniel Mietchen, Junkie.dolphin, Jodi.a.schneider, Adler.fa, OrenBochman, DarTar, Benjamin Mako Hill and Tbayer
Modeling social dynamics in a collaborative environment
editA draft of a letter, submitted for publication, has been posted on ArXiv.[1] The letter reports research on modeling the process of collaborative editing in Wikipedia and similar open-collaboration writing projects. The work builds on previous research by some of its authors on conflict detection in Wikipedia. The authors explore a simple agent-based model of opinion dynamics, in which editors influence each other either by direct communication or by successively editing a shared medium, such as a Wikipedia page. According to the authors, the model, although highly idealized, exhibits a rich behavior that can reproduce, albeit only qualitatively, some key characteristics of conflicts over real-world Wikipedia pages. The authors show that, for a fixed editorial pool with one "mainstream" and two opposing "extremist" groups, consensus is always reached. However, depending on the values of the model's input parameters, achieving consensus may take an extremely long time, and the consensus does not always conform to the initial mainstream view. In the case of a dynamic group, where new editors replace existing ones, consensus may be achieved through a phase of conflict, depending on the rate of new editors joining the editorial pool and on the degree of controversy over the article's topic.
How Wikipedia articles benefit from the availability of public domain resources
editIn a copyright panel at this month's Wikimania, Abhishek Nagaraj – a PhD student and economist from the MIT Sloan School of Management – presented early results from an econometric study of copyright law. The study used data from the English Wikipedia's WikiProject Baseball to try to consider how gains from digitization are moderated by the effects of copyright. Previous work on the economics of copyrights have struggled to disentangle the effects of copyright with the effects of increased access that often coincides with content after it has entered the public domain.
The paper takes advantage of the fact that in 2008, Google digitized and published a large number of magazines as part of the Google Books projects. Among other magazines published were 70 years of back-issues (1945–1970) of Baseball Digest, a magazine that publishes baseball stories, statistics, and photographs. Measuring the effect of digitization, Nagaraj found that the articles on baseball All-Stars from between 1944 and 1984 saw large increases in size (5,200) around the period that the digital Google Books version of Baseball Digest became available. However, because of the law governing copyright expiration, all the issues of Baseball Digest published before 1964 were in the public domain, while issues published after were not. Using the econometric difference in differences technique, Nagaraj compared the different effects of digitization for (1) players who began their professional baseball career after 1964 and as a result had no new digitized public-domain material and (2) players who had played before and were thus more likely to have digitized material about them enter the public domain.
In terms of the effect of copyright, Nagaraj found no effect on the length of Wikipedia articles on public domain status but found a strong effect for images. Wikipedia writers could, presumably, simply rewrite copyrighted material or may not have found the baseball digest form appropriate for the encyclopedia. However, Nagaraj found that the availability of public domain material in baseball digest led to a strong increase in the number of images. Before Google Books published the material, the pre-64 group had an average of 0.183 pictures on their articles and the post 64 group had about 0.158 pictures. In the period after digitization, both groups increased but the older group increased more, to 1.15 pictures per article as opposed to 0.667 images for the more recent players whose Baseball Digest material was still under copyright. Nagaraj also found that those players with public domain material have more traffic to their articles. The essay controls for a large number of variables related to players, their performance and talent, and their potential popularity, as well as for trends in Wikipedia editing.
The presentation slides are available on the Wikimania conference website[2] and a nice journalistic write-up was published by The Atlantic.
Annotating field notes via Wikisource
edit
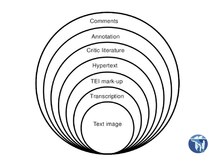
Field notes can be a valuable source of information about meteorological, geological and ecological aspects of the past, and making them accessible by way of Wikisource-based semantic annotation was the focus of a recent study[3] published in ZooKeys as part of a special issue on the digitization of natural history collections. The paper described how the field notes of Junius Henderson from the years 1905–1910 have been transcribed on Wikisource and then semantically annotated, as illustrated in the screenshot. Henderson was an avid collector of molluscs and, while trained as a judge, served as the first curator of the University of Colorado Museum of Natural History. His notebooks are rich in species occurrence records, but also contain occasional gems like this one from September 3, 1905:
| “ | Train again so late as to afford ample opportunity for philosophic meditation upon the motives which inspire railroad people to advertise time which they do not expect to make except under rare circumstances | ” |
The article provides a detailed introduction to the workflows on the English Wikisource in general and to WikiProject Field Notes in particular, which is home to transcriptions of other field notes as well. The data resulting from annotation of the field notes are available in Darwin Core format under a Creative Commons Public Domain Dedication (CC0). This work ties in with discussions that took place at Wikimania about the future of Wikisource, the technical prerequisites and existing tools and initiatives.
Quality of medical information in Wikipedia
editThe quality of medical information in Wikipedia could be vastly improved, based on the results of a recent study of 24 articles in pediatric otolaryngology[4] (more commonly referred to as "ear, nose, and throat" or ENT). The study compared results on common ENT diagnoses from Wikipedia, eMedicine, and MedlinePlus (the three most popular websites, by their determination) and they found that Wikipedia's articles on ENT were the least accurate and had the most errors of the three and that they were in the middle of the other two in regards to readability.
While one of the most referenced sources in this area, Wikipedia had poor content accuracy (46%) compared to the two other frequent sources. MedlinePlus has comparable (49%) accuracy, but was missing 7 topics. The clear leader in accuracy, eMedicine, suffers from a higher reading level. The study provides specific criteria, in section 2.3, which could be considered for evaluation of existing articles. One limitation of the study is that, while suggesting that Wikipedia "suffers from the lack of understanding that a physician-editor may offer", it does not point to information on how to get involved with Wikipedia. Engagement with the pediatric medicine community would be beneficial, especially since about 25% of parents made decisions about their children's care in part based on online information.
Emotions and dialogue
editA forthcoming paper at this year's WikiSym conference investigates the emotions expressed in article and user talk pages[5]. "Administrators tend to be more positive than regular users", and the paper suggests that "as women gain experience in Wikipedia they tend to adopt the emotional tone of administrators", for instance linking to policy at more than twice the rate as males. Due to the likelihood of women to interact with other women, they suggest gender-aware recruiting to address the gender gap.
The authors point out the utility of positive emotion in keeping discussions on track, and suggest that experienced editors should be encouraged to maintain a positive climate. To determine users' gender, they used a crowd-sourced study through Crowdflower. Emotions are determined using the ANEW wordlist which distinguishes the range of emotional variability, based on valence, arousal, and dominance. The paper notes that policy mentions tend to have "a remarkably positive and dominant tone, and with stronger emotional load than in the rest of the discussion'".
Editor collaboration patterns
editA paper from the University of Alberta addresses the difficulty with analyzing edit histories and finding conflict in particular [6]. They use terms indicating content-based agreement (e.g. "add", "fix", "spellcheck", "copy", and "move") and disagreement ("uncited", "fact", "is not", "bias", "claim", "revert", and "see talk page"). They define conflicting interactions as those that revert, or delete content, or use more negative terms than positive terms. They find that this is a useful way to identify controversial articles.
Why does the number of Wikipedia readers rise while the number of editors doesn't?
editA student paper for a course on "Project in Mining Massive Data Sets" at Stanford University, titled "Wikipedia Mathematical Models and Reversion Prediction"[7] tries to use mathematical models "to explain why the amount of [editors on the English Wikipedia] stops increasing, whereas the amount of viewers keeps increase", and "to predict if an edit will be reverted." The researchers used Elastic MapReduce on Amazon's servers to carry out this research. The paper is a bit confused since the researchers are more interested in models and validation than explaining the phenomena.
The first part of the paper includes two models for examining the relation of visitors to editors in Wikipedia's community. The first model makes the assumption that editors act as predators and articles have the role of prey. However this model did not fit the data. The second model used a linear regression between a number of factors which allow to model the community's statistics over time. The model is then tested using simulation and seems to present accurate results.
In the second part of the paper, three models were used predict which edits will get reverted. The models were trained using 24 features, classified either as edit, editor or article based. E.g. an article's age; its edit count; number of editors participating in editing; number of articles the editor has edited; change in information compared to previous status. The outcome of the prediction which used three machine learning algorithms achieved about 75% accuracy and another interesting conclusion was that the ability to detect reversion has not changed much over time.
Briefly
edit- What was the most influential paper ever about Wikipedia and related topics?: Wikimedia France is currently seeking nominations for its Research Award (which comes with a grant of €2500), which aims "to reward the most influential research paper on Wikimedia projects" published between 2003 and 2011. In the coming years, the scope is to be widened to include free knowledge projects more generally. Submission deadline for paper nominations is August 7. The winner shall be announced in November.
- Retrieving information missing from Wikipedia articles: A paper presented at the 6th International Conference on Ubiquitous Information Management and Communication presents a technique developed by researchers at Kyoto University to compare Wikipedia articles with matching sources retrieved via search engines and identify, via topic modeling, to what extent the external source includes complementary information not covered in the article.[8] The paper then proposes a method to extract sentences from these sources and rank them to facilitate editorial work. Two case studies are discussed analyzing the Yutaka Taniyama and Influvac articles from the English Wikipedia.
- Mining Wikipedia for common traits of notable individuals: Researcher Pauline C. Ng presented a paper at ICWSM '12 showcasing the potential of using Wikipedia as a corpus of data to study the common characteristics of "notable individuals".[9] Names and birth locations of a list of 40,250 people born in the United States from 1940–1989 and with a Wikipedia article were compared against census data. The analysis reveals interesting patterns such as the fact that "people with rare names [are] more than 2x likely to appear in Wikipedia" or that "people with nicknames are more likely to be in Wikipedia", but with a significantly more pronounced effect for male than female individuals. The author suggests that mining Wikipedia biographies may help "discover novel characteristics associated with positive life outcomes". The main findings of the paper are summarized in this blog post.
- 2012 Aurora shooting: Brian Keegan, who has published a series of previous articles on coverage of breaking news topics in Wikipedia (see e.g. our past coverage: "High-tempo contributions: Who edits breaking news articles?"), published a series an analyses and a series of graphs on the first several days of responses and article writing on Wikipedia to cover the 2012 Aurora shootings on English Wikipedia.[10] Several participants responded to Keegan in comments on his blog. Taha Yasseri published a graph of the increase in the number of articles on the shootings in different languages.[11]
- Detecting featured articles using fuzzy logic: A paper[12] by two Bangkok-based computer scientists constructed a fuzzy logic ruleset to discern the featured articles on the Thai Wikipedia (88 at the time of the study) from non-featured articles (100 in the examined sample). Using 26 different rules, from unsurprising ones such as the assumption that an article with few footnotes probably does not have featured status, to more complicated criteria involving the most frequent and second most frequent editor of the article, they achieved 100% recall (i.e. detecting all featured articles) and 86% precision (i.e. of the articles detected as having featured quality, 86% actually had featured article status). This compared favorably to a different detection method (which clustered articles according to their distance in a similarity measure that the authors do not specify), supporting the authors' thesis that fuzzy logic is a better approach to the problem, because "the quality of Wikipedia articles should be graded [by] more than two values (good or not good)". (See also coverage of an earlier paper with similar goal: "Lexical clues" predict article quality)
References
edit- ↑ Török, J.; Iñiguez, G.; Yasseri, T.; San Miguel, M.; Kaski, K.; Kertész, J. (2012) "Opinions, Conflicts and Consensus: Modeling Social Dynamics in a Collaborative Environment". ArXiv.

- ↑ Nagaraj, Abhishek. (2012) "The effect of copyright law on the reuse of digital content". Wikimania 2012, July 12–15 2012, George Washington University.
- ↑ Thomer, A.; Vaidya, G.; Guralnick, R.; Bloom, D.; Russell, L. (2012). "From documents to datasets: A MediaWiki-based method of annotating and extracting species observations in century-old field notebooks". ZooKeys 209: 235. doi:10.3897/zookeys.209.3247.
- ↑ Volsky, P. G.; Baldassari, C. M.; Mushti, S.; Derkay, C. S. (2012). "Quality of Internet information in pediatric otolaryngology: A comparison of three most referenced websites". International Journal of Pediatric Otorhinolaryngology. doi:10.1016/j.ijporl.2012.05.026.

- ↑ Laniado, David; Castillo, Carlos; Kaltenbrunner, Andreas; Fuster Morell, Mayo (Aug 27–29, 2012). "Emotions and dialogue in a peer-production community: the case of Wikipedia" (PDF). WikiSym. Linz, Austria: ACM Press.
- ↑ Sepehri-Rad, Hoda; Makazhanov, Aibek; Rafiei, Davood; Barbosa, Denilson. (2012) "Leveraging Editor Collaboration Patterns in Wikipedia". In Proceedings of the 23rd ACM conference on Hypertext and Social Media, pp. 13-22. doi:10.1145/2309996.2310001
- ↑ Jia Ji; Bing Han; Dingyi Li. (2012) "Wikipedia Mathematical Models and Reversion Prediction"
- ↑ Eklou, D., Asano, Y., & Yoshikawa, M. (2012). How the web can help Wikipedia: a study on information complementation of Wikipedia by the web. Proceedings of the 6th International Conference on Ubiquitous Information Management and Communication – ICUIMC ’12 (p. 1). New York, New York, USA: ACM Press. doi:10.1145/2184751.2184763
- ↑ Ng, P. C. (2012). "What Kobe Bryant and Britney Spears Have in Common: Mining Wikipedia for Characteristics of Notable Individuals". Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media.
- ↑ Keegan, Brian. (July 21, 2012) "Aurora shootings."
- ↑ Yasseri, Taha. (2012) "Number of covering WPs vs. time" [1].
- ↑ Saengthongpattana, Kanchana; Soonthornphisaj, Nuanwan. (2012) "Thai Wikipedia Quality Measurement using Fuzzy Logic" 26th Annual Conference of the Japanese Society for Artificial Intelligence, June 12-15, 2012, Yamaguchi, Japan.
![[1]](http://wwm.phy.bme.hu/figs/aurora.png){kind=link}
Wikimedia Research Newsletter
Vol: 2 • Issue: 7 • July 2012
About • Subscribe: Email ![]()
![]()
![]() •
[archives] • [Signpost edition] • [contribute] • [research index]
•
[archives] • [Signpost edition] • [contribute] • [research index]