User:Diegodlh/Web2Cit/Midpoint
![]() This project is funded by a Project Grant
This project is funded by a Project Grant
| proposal | midpoint report |
- Draft report
Welcome to this project's midpoint report! This report shares progress and learning from the first half of the grant period.
Summary
editIn a few short sentences or bullet points, give the main highlights of what happened with your project so far. Our project involves three main subprojects:
- Development
- Web2Cit translation is already available for early adopters willing to use before the visual editor is released. Just prepend
https://web2cit.toolforge.org/to any URL and you will get a translation result, based on collaboratively defined configuration files, that you can use with Wikipedia's automatic citation generator. - All source code has been published under a GPL free software license on Wikimedia's recent Gitlab installation, making this one of the first projects to be hosted there.
- Web2Cit translation is already available for early adopters willing to use before the visual editor is released. Just prepend
- Communications & community
- An Advisory Board has been put together, with members from diverse backgrounds, to "help us build sustainability and community involvement for this project".
- Technical and non-technical, written and video resources have been published.
- Research
- Our automated script is partially complete, supporting:
- getting Wikitext from a series of featured articles;
- extracting metadata from citation templates; and
- retrieving Citoid data for extracted URLs.
- Our preliminary results have been shared with our Advisory Board and submitted to WikiWorkshop 2022.
- Our automated script is partially complete, supporting:
Methods and activities
editHow have you setup your project, and what work has been completed so far?
Describe how you've setup your experiment or pilot, sharing your key focuses so far and including links to any background research or past learning that has guided your decisions. List and describe the activities you've undertaken as part of your project to this point.
Project management
edit- Phabricator setup. In the Cita project, also funded by the Wikimedia Foundation, using an issue tracker to keep track of tasks, including bugs, feature requests and general ideas (regardless of whether they would be taken care of during the grant period or not) was of great help. For example, after the project ended, a user started addressing some of these tasks, and he is now part of the project. Based on this experience, we set up Phabricator project tags for the Web2Cit project and its sub-projects.
Development
edit- Initial planning and design. Long before starting to code anything at all, we tried to carefully plan and design the overall Web2Cit ecosystem and software architecture, to minimize the chances of encountering unexpected scenarios upon coding that would force us start everything from scratch.
- Minimum viable product. Part of this early planning included delimiting what would be our Minimum viable product, as partially documented in our Technical specifications,[1] and discussed in our Advisory Board meetings. This included supporting a subset of citation metadata to begin with, based on community consensus,[2] previous research,[3] and third-party requirements.[4]
- Codebase:
- Gitlab repository. Based on our previous experience with Github and Gitlab (and lack of experience with Gerrit), and considering that Wikimedia had set up a custom installation of Gitlab, we decided to host our source code there, becoming one of the first projects to do so.
- GPL license. Our code has been published under the GNU General Public License v3, to make sure others can freely reuse it, under the same conditions of freedom.
- Automated tests. In a lead developer's previous project Cita, lack of time and knowledge resulted in the absence of automated tests, which is currently somewhat hindering project evolution. To prevent this from happening in Web2Cit, we included automated tests from the beginning.
- Code formatter. Based on previous experience with Cita as well, we decided to use the Prettier code formatter.zref>https://prettier.io/</ref> This should help us focus on the important aspects when discussing changes to the code, rather than wasting time on coding style.
- TypeScript. Because we wanted our translation editor to run on web browsers, and because it would consume our core library, which in turn would be used by other components of the Web2Cit ecosystem, we decided to use JavaScript for all our codebases. We were in doubt whether to use TypeScript (a JavaScript superset supporting static typing) because we were afraid it could deter potential contributors (given its relatively higher complexity), but in the end we decided to do so, given its potential to prevent bugs and increase code quality.
Research
edit- Study design:
- Accurate citation metadata. One of the main concerns of the research sub-project was the validity of our assumption that we could rely on reference metadata extracted from citation templates as a source of "correct" metadata. This was discussed extensively in our Advisory Board, both online and offline, finally deciding to focus on citations from featured articles online, assuming their overall quality would be higher.
- Citation templates and parameters. Another aspect of debate was how to specifically identify citation templates, among all Wikipedia templates available, and their relevant parameters. After some discussion, we decided to manually create a collaborative list of citation templates from different language Wikipedias, including the parameters that map to any of the basic fields we are interested in.[5] The automated script then uses the latest version of this list to extract citation metadata.
- Setup
- PAWS Jupyter notebook. We are using a Jupyter notebook to write our automated script, given the possibility to interleave code, comments and results. As mentioned in the Learning section below, using Wikimedia-hosted Jupyter notebooks (PAWS) greatly improved performance.
- Batch Citoid request optimization. One part of the research tasks involves getting citation metadata for thousands of reference URLs extracted from the wikitext. To avoid disruption of the Citoid service, we brought this to discussion in Phabricator, which let us make decisions to better optimize this process.
- Implementation
- Advanced implementation. The automated script has been largely implemented already. More details available in the Outcomes section below.
Communication & Community
edit- Advisory board. We have put together an Advisory Board with 9 members from diverse backgrounds, opened a mailing list, and organized regular meetings, having held 4 meetings so far.
- Resources and documentation. We have created and published technical and non-technical resources, as described in detail in the Outcomes section below.
- WikiConference NA. We presented the project at the 2021 edition of this conference.[6]
Midpoint outcomes
editWhat are the results of your project or any experiments you’ve worked on so far?
Please discuss anything you have created or changed (organized, built, grown, etc) as a result of your project to date.
Development
editCore library
editThe Web2Cit core library (formerly "translation engine") is the central component of the Web2Cit ecosystem, used by all other components (translation server, translation editor and monitor). The initial version supports:
- Fetching configuration files from our repository in Meta.
- Fetching HTML and Citoid responses from target webpages.
- Using template and pattern configurations to provide translation results.
- A selection and transformation step framework with several types already supported, and easily expandable to support others in the future.
More information about how Web2Cit translation works can be found in our overview video.[7]
-
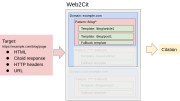 Web2Cit translation overview
Web2Cit translation overview -
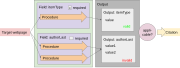 Web2Cit translation template representation
Web2Cit translation template representation -
 Web2Cit translation procedure representation
Web2Cit translation procedure representation



Translation server
editThe Web2Cit translation server (formerly "translation API") is a web service that uses our core library to return Web2Cit translations for any target webpage. The initial version includes:
- A Toolforge-hosted translation endpoint that can be used by simply prepending
https://web2cit.toolforge.org/to the URL that wants to be translated. - Result pages including embedded metadata that can be used by Wikipedia citation generator, Zotero connectors,[8] among others.
Translation editor
editThe Web2Cit translation editor (aka "frontend") is a central component of the Web2Cit ecosystem that will provide a visual way to edit Web2Cit configuration for different domains. Development is still pending (see Next steps section), but a mockup showing how it will look like is already available in the resources section of our landing page.
Translation monitor
editThe Web2Cit translation monitor (formerly "cache") is the part of the Web2Cit ecosystem that will monitor the overall status of the Web2Cit translation system by regularly fetching test configuration files from Meta (which indicate what the translation output should be for different test webpages) and comparing them against what Web2Cit is actually returning. Although this has not been developed yet (see Next steps section) we have already documented how the configuration files should look like in our guidelines for Early adopters.
Research
edit
The goal of our research sub-project is to describe the width and nature of the current Citoid coverage gap (i.e., webpages for which Citoid returns wrong or incomplete metadata), by developing an automated script that can be run now and any time in the future, after Web2Cit has been implemented. So far, we have:
- Created a list of citation templates and relevant parameters for different language Wikipedias.[5]
- Partially developed the automated script (hosted on Wikimedia's PAWS), including:
- Retrieving the list of featured articles for a predefined set of different language Wikipedias.
- Fetching the wikitext for these articles.
- Identifying citation templates based on our collaborative list (see above).
- Extracting relevant metadata from them based on parameter information from the same collaborative list.
- Getting citation metadata from the Citoid service for the reference URLs extracted.
- So far we have extracted 450k references from +10k featured articles, and we are in the process of getting their metadata from Citoid. These preliminary results have been submitted to WikiWorkshop 2022, an yearly "forum bringing together researchers exploring all aspects of Wikimedia projects."[9]
Communication and community
editThe main outcomes of our Communications & Community sub-project include:
- The creation of an Advisory Board formed by people from diverse backgrounds with whom we discuss relevant decisions and news of our project, either on our mailing list, or at our regular meetings.
- The publication of technical and non-technical resources and documentation:
- A (ready for translation) landing page.
- A mockup of the translation editor (aka "frontend"), including a recording of its walk-through presentation
- Slides of our first Advisory Board meetings, including a general overview of the Web2Cit ecosystem.
- A video overview of Web2Cit translation.[7]
- Draft technical specifications, including general and core-specific documents.
- A (ready for translation) guide for early adopters would like to start using Web2Cit.
- The creation of a collaborative list of problematic URLs,[10] which may be used by Web2Cit contributors to start defining domain configurations.
- The configuration of Phabricator project tags and workboards to keep track of and engage the community around project tasks, including feature requests, bug reports, etc.
Early adopter guidelines
editWe published a guideline, including a series of companion videos, for those interested in starting to use Web2Cit. Although this requires more advanced technical skills than those that will be needed once the translation editor is available, we expect the barrier to be lower than it currently is for developing Citoid/Zotero translators.[11]
These guideline and videos guide potential contributors through the process of using Web2Cit to fix Citoid/Zotero translation for problematic URLs. Consider the following example, covered in detail in our hands-on video:[12]
- A webpage (https://www.elobservador.com.uy/nota/salto-alcanzo-los-42-5-c-y-rompio-el-record-historico-de-temperatura-en-enero-en-uruguay-20221147523) from Uruguayan newspaper "El observador" is found for which Citoid returns partially correct citation metadata. Namely, the title and publication title are correct, but the item type and authors are wrong, and the publication date is missing.
- Expected translation results are indicated in the
tests.jsonconfiguration file for thewww.elobservador.com.uydomain. This will help ourselves and other contributors with defining translation configuration, and the Web2Cit monitor with early detecting translation errors. - Then, a translation template is defined in the
templates.jsonconfiguration file, indicating how to extract the expected results from the template webpage; in other words, how to make the test defined above pass. - Finally, the Web2Cit translation server address (
https://web2cit.toolforge.org/) is prepended to the target URL and given to Wikipedia's automatic citation generator, which then returns a formatted citation with metadata from Web2Cit translation results.
-
 Automatic citation for an article from El Observador, using Citoid.
Automatic citation for an article from El Observador, using Citoid. -
 Automatic citation for the same article, using Web2Cit.
Automatic citation for the same article, using Web2Cit.


Note that not only can the template be used to translate the template itself, but also any other webpages with a similar format from the same domain.
Finances
editPlease take some time to update the table in your project finances page. Check that you’ve listed all approved and actual expenditures as instructed. If there are differences between the planned and actual use of funds, please use the column provided there to explain them.
Then, answer the following question here: Have you spent your funds according to plan so far? Please briefly describe any major changes to budget or expenditures that you anticipate for the second half of your project.
- Development. Development funds have been spent according to plan so far, having spent approximately 40% ($18,000) of the budgeted amount ($43,560).
- Communications & Community. To minimize wire transfer costs, community engagement funds have been paid in advance to Evelin Heidel, the Communications & Community Manager. In this case we were able to reliably do so because she is also one of the project grantees. Nonetheless, we understand that in larger projects involving more people a stricter approach, involving multiple payment installments, would be more appropriate.
- Research. We underestimated the number of hours needed for the research sub-project. Our updated estimate doubles what we had originally planned. We are very satisfied with the research team work and their results so far, and we would like to use part of our contingency funds to increase the research budget accordingly. This will be requested in the proposal's main discussion page.
- Project management. As mentioned in the Learning section below, this project reminded us how demanding project management is. We do not have a separate item in the budget for this, and this work has been taken up by the lead developer as planned. However, future projects may want to consider having a separate role and budget for these tasks.
Learning
editThe best thing about trying something new is that you learn from it. We want to follow in your footsteps and learn along with you, and we want to know that you are taking enough risks to learn something really interesting! Please use the below sections to describe what is working and what you plan to change for the second half of your project.
What are the challenges
editWhat challenges or obstacles have you encountered? What will you do differently going forward? Please list these as short bullet points.
Project management
edit- Workload. As mentioned above, this project reminded us of how much time and effort project management requires. However, we had not planned for project management hours in our proposal, nor had we set a separate budget line for it. Going forward, in future projects, we would consider this role separately, allocating specific time and budget to these tasks, as done in other projects (see for example the budget of the Structured data on Wikimedia Commons functionalities in OpenRefine project).
- Task tracking. From a project management perspective, keeping track of our pending tasks across different sub-projects and teams represents a challenge. We try to use Phabricator as our central task tracker, but it works differently for different sub-projects, because understandably some teams find it more useful than others. Going forward, we plan to continue using Phabricator as our central point of coordination, providing a general overview of pending tasks, in addition to other task tracking strategies that individual sub-project may use.
Development
edit- Web2Cit collaboration strategy. Coming up with a design that allows multiple users use and collaboratively tweak Web2Cit translation was one of the design challenges of this project. Our original idea involved multiple configurations per domain, each specified by a different Web2Cit collaborator, and voted up or down by other users. Although this seemed more robust against accidental or intentional disruptions, it was not true collaboration. In the end we decided to follow a more wiki-like approach, having a single set of configuration files collaboratively edited and patrolled by the community, and splitting configuration into three files per domain to enable finer-grained permissions in case of repeated vandalism. In addition, going forward, the translation monitor to be developed (see Next steps section) should help us early detect accidental or intentional disruptions to the translation system.
- Switching from planning to implementing. As mentioned above, in this project we tried to invest as much time as possible in carefully thinking, researching and designing before starting to code. At the beginning of the project, the value of doing this was undoubtedly high. However, as time passed, the perceived benefit per unit of time invested to this kind of tasks seemed to become smaller and smaller, and we would start wondering when it would be worth it to stop exploring and start doing the actual work. Establishing the optimal point where the overall design should be considered finished, was (as it usually happens to me in this kind of projects) a challenge in this project.
- Hiring of an additional programmer. The original plan was to hire an additional programmer. However, I have been continuously postponing this for at least two main reasons. First, as mentioned in the project management challenges section above, the project involves a considerable project management workload, which is mostly taken care of by me (Diego) in addition to my lead developer role, as planned. Even though hiring a second programmer would reduce my programming workload, it would probably increase my management workload, which is already high, and which I do not have as much experience with, nor do I enjoy as much, as programming. Secondly, even though I have been working as a programmer for the last two years, I still feel insecure about some of my skills, and I find the process of recruiting and hiring potential candidates intimidating. Having said all of this, I really want to have the valuable experience of leading a small development team, and I still consider the possibility of hiring an additional programmer for the second part of the project. However, considering the reasons outlined, I have reconsidered the tasks that may be assigned to them, such as maintining and improving what we already have (namely, the core library and the translation server) instead of developing the missing parts (the editor and the monitor) from scratch.
Communications & Community
edit- Feedback. So far our Advisory Board meetings have been taking place approximately every two months, and they have been so packed with information that we often do not have enough time for long discussions. Even though some of them occur on our mailing list, we understand that not everyone can invest enough personal time to reading and replying to emails. Going forward we plan to share some resources before the meetings more often, and try and discuss them during the meetings, instead of going through them in detail. We may also consider meeting more often as well.
Research
edit- Wikimedia experience. One of the challenges faced by the members of the research team was the amount of Wikimedia knowledge needed for the project, including dealing with APIs, understanding the diversity of citation practices among the community of editors, understanding citation templates and how the community use them, etc. Fortunately, the team managed to grasp this successfully, gaining knowledge and experience that will hopefully help them in future Wikimedia projects that they may participate in.
- Reliability of citation data. One of the main challenges of the research sub-project is how to get enough accurate citation metadata to compare against what Citoid returns. Because we want our procedures to be automatic, so they can be run again any time in the future, manual approaches were discouraged. Our initial approach was to use Wikipedia references, assuming that the community would have curated their metadata with time. However, we knew that this assumption could we weak, so we raised it for discussion to our Advisory Board. With their input, we finally decided to focus on featured articles only, assuming that their overall quality (including quality of citation metadata) would be higher.
What is working well
editWhat have you found works best so far? To help spread successful strategies so that they can be of use to others in the movement, rather than writing lots of text here, we'd like you to share your finding in the form of a link to a learning pattern.
Project management
edit- Documenting discussions. Our project includes three sub-projects. We meet regularly with team members to discuss updates and plan future moves, and we keep notes of every meeting to keep better track of what has been discussed previously. For example, the notes of our research team meetings have helped with writing our submission to WikiWorkshop 2021. This is related to learning pattern Keeping documentation of discussions with team.
- Tell people. As mentioned in the Challenges section, the development branch was 2 months behind because the lead developer was writing his PhD thesis and it was taking him longer than originally expected. This was a source of frustration because he could not postpone writing the thesis any longer, but at the same time each time he sat to write it he felt the weight of the project falling behind further and further. Following the advice of Scann, and as described in the invaluable When things go wrong, just tell people learning pattern, he finally decided to ask for a two-month extension of the midpoint report. The request was accepted, and after that frustration and stress disappeared. Finally, the milestones promised for the midpoint report [| were met] after the two-month additional period, as expected.
In addition, in the early stages of this project I was also finishing my PhD thesis (as reported here), which made the development branch fall behind even further. However, such detailed planning made the actual development move much faster than I had ever imagined. Everything had been planned with so much detail in advance, that very little had to be changed during development. Moving forward, I only have my dissertation left, and the planning phase of the editor should be smaller, given that it is just a scaffold around the core library, so I do not expect large delays as in the first stage.
- Budget updates. As mentioned in the Finances section, even though all parts agreed that the time estimation for the research subproject was OK, we then found out that it was taking longer than originally planned. As documented in the Grant projects are not startups, project management decided to ask that part of our emergency funds should be used to increase the research budget, as it would have been unfair to do otherwise.
- Boldness and clarity. As a project manager I try as hard as I can to listen to all voices and to understand that there are other ways (often better) of doing things than what I had originally planned, leaving enough room for creativity and detour. However, as the project manager, I also learned that sometimes it is necessary to take final decisions for what one is responsible in the end, such as task priority. All in all, being clear about the expectations is a fundamental piece of communication with the team, as described in learning pattern Clarity of expectations when setting up a partnership
Development
edit- Carefully planning and designing in advance. As mentioned in previous sections, in the early phases of this project, we carefully thought, designed and planned the software architecture. Although this process (and partially documenting it) took quite long, giving the feeling that the project would never actually become true, it turned out to be an excellent investment, given than later on development proceeded very smoothly, and very few things (all of them quite minor) had to be changed during development phase. Careful planning also helped with implementing a small minimum viable product, yet ready to grow to a much larger and feature-complete product in the future, without having to change the core architecture design. Like building a small house ready to grow to a huge one.
- Using TypeScript. Using TypeScript instead of JavaScript was also a good decision. Although learning this superset required some extra time, no doubt it saved even more time because many bugs could be caught and corrected while writing code.
- Using automated tests. Implement automatic tests from the beginning. Jest was easier to start with, given my lack of experience with automatic tests. But now that I've learned more, I may use simpler and better established tools (such as Mocha, Chai, ...) in the future (this project and others)
- Hosting on Toolforge. This was the lead developer's first experience with Toolforge, and it was a really good one. It turned out to be a much more powerful platform than I had expected it to be, and it gave great opportunities to learn some Kubernetes, which I had long wanted to.
Communications & Community
edit- Advisory board. As suggested by grant officer Marti Johnson, we put together and Advisory Board with people from diverse backgrounds. This has and will help us with:
- Thinking and discussing challenging aspects of the project. Learning patterns Expert involvement, Sustaining dialogue with your community, and Feedback cycle are directly related to this.
- Spreading the voice to relevant communities, as suggested by learning pattern Let the community know.
- Supporting the project once the grant finishes, related to learning pattern Community impact.
- Video documentation. Our project includes publishing documentation, such as technical documentation and user guidelines. Even though we acknowledge that in some cases written documentation may be better, as it can be kept up to date more easily, sometimes the time needed to write documentation hinders documentation at all. For this cases, we have learned that releasing video documentation may be a good middle point. On the one hand, it is much easier to create. On the other hand, it may be later on adapter by project members and volunteers who may create written documentation based on that. Finally, sometimes it may also be easier to consume and follow. Take for example our Early adopters hands-on demonstration.
Research
edit- PAWS. The research team uses Jupyter notebooks to write the automated script. This is very useful because it interleaves code, comments and results. At one point we decided to try PAWS, the Jupyter notebook hosted by Wikimedia, and we saw impressive improvements in speed, as mentioned in our January report.
Next steps and opportunities
editWhat are the next steps and opportunities you’ll be focusing on for the second half of your project? Please list these as short bullet points.
- Development
- Develop and release the translation editor to enable editing configuration files visually, including internationalization and translation. We updated the name and the estimated date in the corresponding milestone.
- Add core library support for translation tests (phab:T302722)
- Publish core library as npm package for easier reuse by other software projects (phab:T303294)
- Continue testing and fixing bugs in core library and translation server
- Internationalize and translate translation server result page
- Continue writing technical documentation, including guidelines for developers and architecture information
- Develop and kick off Web2Cit monitor. We updated the name and the estimated date in the corresponding milestone.
- Update frontend and monitor milestone date
- Research
- Fetch Citoid metadata for all 450k reference URLs, following the optimization strategies discussed in phab:T301510
- Compare Citoid metadata vs extracted metadata to estimate Citoid's coverage gap. Group data by Wikipedia language and reference domain.
- Write and publish research results
- Communication & community
- Create and publish end-user guideline to:
- Integrate Web2Cit translation to Wikipedia editing workflow
- Use Web2Cit frontend to visually update translation configuration
- Use Web2Cit monitor to identify and fix translation problems
- Organize workshops for early adopters and for end users :
- Some for early adopters and some for end-users
- Tackle problematic URLs collected in our collaborative list, and those already worked on by Andrew Lih and collaborators
- Use output from research results as well
- Recruit translators to help us translate the Web2Cit frontend interface to other languages
- Create and publish end-user guideline to:
Grantee reflection
editWe’d love to hear any thoughts you have on how the experience of being an grantee has been so far. What is one thing that surprised you, or that you particularly enjoyed from the past 3 months?
Diegodlh's reflections
editI am really enjoying working on this project so far. On the one hand, as the development lead I am learning a lot about programming, including automated tests and TypeScript. Additionally, it let me understand how much I enjoy the software design phase, and I am willing to learn more about design patterns, and software architecture in general now.
On the other hand, as the project manager, this is being a great experience as well. It is the second time I am leading a team of colleagues, and it is very challenging and gratifying. It has further highlighted to me how management is a role on its one, how one has to continuously learn how to do it right.
For example, When we started, I wanted to enrich the experience by having a team of developers (me plus second developer) to lead. However, with time, it turned out that project management was already quite complex, with three separate projects to coordinate, with 4 people in total. So, even though I have not yet fully discarded having a second developer, I fear that hiring another developer may take even more management time, which may exceed the time needed to do it myself at this point.
I am very happy with how the project is developing in all edges. I am glad to see the software design so carefully planned finally working in our first version of the core library. Even though I took care to carefully consider the proposal before starting, as usual one is never 100% sure that one won't find an unforeseen obstacle that makes everything collapse. Fortunately everything has run (relatively) so smoothly!
I am happy to see the research team working so proactively and independently, even though we are meeting on a monthly basis. They have submitted a long abstract to WikiWorkshop 2022! This is the first time this has happened to me, that a team under my leadership is sharing their results with a wider audience :)
And I think we are starting to build a community of interested and enthusiastic people around the project, thanks to Evelin. We already have something to show, and I can't wait to start with our workshops, and to see how people begin to use Web2Cit to improve Wikipedia's compatibility with other sources.
Scann's reflections
editReferences
edit- ↑ Work-in-progress technical specifications
- ↑ Citation templates' required and suggested parameters
- ↑ Andrew Lih's four news' citation components
- ↑ Google Scholar required tags
- ↑ a b Collaborative list of citation templates
- ↑ Web2Cit at WikiConference NA 2021
- ↑ a b How does Web2Cit work? An overview
- ↑ Zotero connectors
- ↑ WikiWorkshop 2022
- ↑ Collaborative list of problematic URLs
- ↑ Zotero translator development documentation
- ↑ Hands-on demonstration for Web2Cit early adopters