Research:Understanding hoax articles on English Wikipedia
Wikipedia is a great source of information on almost everything there is. However, since Wikipedia can be edited by anyone, it is easy to insert false information. Such information can mislead readers and cause trouble. For instance, a hoax article about an Australian aboriginal god lasted on Wikipedia for over 9 years and 9 months and was mentioned in a book too. [1] Moreover, the existence of false information questions the credibility of any article on Wikipedia. Therefore, it is important to detect and delete these hoaxes early in their development cycle to prevent the spread of misinformation.
According to Wikipedia policies, "a hoax is an attempt to trick an audience into believing that something false is real".[2] In this research, we propose to study hoax articles and revisions in the English Wikipedia through their edit history to understand how they are created and eventually caught. We would like to understand the characteristics of hoax articles and how they differ from legitimate articles, in order to build a classifier that identifies these articles soon after they are created. We find striking differences in terms of article structure and content, embeddedness in the rest of Wikipedia and the attributes of the editor who created the article.
Before understanding the differences between hoax and legitimate articles, we first measure the real-world impact of the hoax articles in terms of survival time, pageviews and inlinks from the web. We find that, while most of the Wikipedia articles are deleted very quickly, a handful of articles sneak through, survive for a long time and are cited well from across the web.
Furthermore, we evaluate a task involving humans distinguishing a hoax from a non-hoax, in order to understand the factors that influence a human to decide whether an article is hoax or not.
Please refer to the publication section for the research paper and presentation.
Data Collection
editComplete edit history of articles in the English Wikipedia that were marked with templates such as en:Template:Hoax, en:Template:Db-hoax, and similar tags, and eventually deleted for being hoaxes. This requires access to non-public data, since hoax articles are often deleted, yet deleted revisions are not contained in the publicly available edit history. Also revisions that are deleted because of containing hoax information are needed.
Dataset Creation
editFirstly, we created the datasets that we would be using for understanding the creation of hoax articles. For this we selected a set of hoax articles on English Wikipedia and a set with equal number of legitimate articles (ones that are never flagged as hoax). Furthermore, to understand what humans consider to be hoax, we created a set of articles that were wrongly flagged as hoax.
All hoax articles go through their life cycle of article creation, patrol, flagging and eventual deletion. We only consider those articles that complete this life cycle, i.e. go through each step, and for non-hoaxes, we consider those that were created and patrolled.
Creation of the hoax article set:
editWe selected all the articles that were deleted due to hoax. These are the set of articles whose deletion logs have the word “hoax”. In addition, we take those deleted articles whose revision comments have the word “hoax”. However, this set of articles may contain false positives (articles that are not actually deleted for hoax). So, we filter them to only keep the articles that have the hoax template in any of their revisions. Furthermore, since the hoax articles may survive because no one actually looks at them, we only consider the hoax articles that were patrolled.
Cleaning up hoax article set
editWe recently realized that while creating the hoax articles, we had unknowingly added false positives due to two reasons:
- An article may be deleted multiple times, and may even have different content. Let us call each of those as a version of the article. Not all of the versions of an article may be deleted for hoax. So, we only keep those versions that were deleted due to hoax, and treat two instances of hoax for the same article as two separate instances of hoax.
- When we filtered articles such that we `only keep the articles that have the hoax template in any of their revisions', we also included articles which were tagged with the hoax template, but the template was removed, mostly because the article did not qualify for the template. So now we only keep instances that have the hoax templates till the very last revision of the article before deletion.
After these conditions, there are a total of 21,218 hoax articles.
Passing vs failing patrol
editWe further categorize these articles into whether they pass or fail the patrol stage. The articles that fail patrol were marked with the hoax tag by the patroller, while the ones that pass were not. Hoax articles that were already marked as suspicious prior to patrolling are ambiguous, so we focus only on the remaining ones. This gives 2,692 hoax articles that pass patrol, and 12,901 that fail.
Creation of the legitimate article set:
editWe randomly selected an equal number of articles that are not deleted and none of whose revisions have the hoax template. Additionally, we selected these articles with the constraint such that all hoax articles have a legitimate article that is created on the same day, and they must have been patrolled. This is the set of legitimate articles that we will use for comparing with the hoax articles.
Creation of “wrongly flagged as hoax” article set:
editMany times human judgement is not correct - an article may be suspected of being a hoax, but after digging deeper, it indeed is not. These are cases when the article is wrongly flagged as hoax at some point, but is eventually cleared of the charge. To create this set of articles, we selected those articles that have the hoax template in any of their revision, but the article is not deleted. To prevent including the articles with ongoing hoax investigations, we only considered the articles from which the hoax template is removed. Additionally, these articles must also have been patrolled. This gives a total of 960 articles.
Real-world impact of hoaxes
editMisinformation is detrimental if it affects many people. Hoaxes that are deleted even before they get significant attention are not impactful. The more exposure hoaxes get, the more we should care about finding and removing them. Hence, inspired by the aforementioned Jimmy Wales quote that “[t]he worst hoaxes are those which (a) last for a long time, (b) receive significant traffic, and (c) are relied upon by credible news media”. [3] Therefore, we measure the impact of hoax in terms of how long they survive, how often they are viewed, and how heavily they are cited from the Web.
Time till discovery
editSince November 2007, all articles are patrolled by trusted users. Following the patrol, the hoax article would eventually be uncovered and flagged. We consider the impact, in this part, in terms of how long the hoax goes without being flagged from the time it was patrolled. We find that most articles (90%) are flagged within an hour of patrol. However, thereafter the detection rate slows down considerably - it takes a day to catch 92% of eventually detected hoaxes, 94% are detected in a week and 96% in a month. One in a hundred even survive for over an year.
The cumulative distribution function (CDF) plot shows the fraction of articles that survive until a particular time after patrol.

Pageviews
editIn this part, we quantify the impact of the hoax article in terms of the amount of traffic it gets. The more traffic it gets, the more the false information it contains spreads, while at the same time increasing the risk of it being caught. To measure the traffic, we consider the daily traffic the article receives from the time it was patrolled till it was flagged. To remove the pageviews due to these two processes, we remove the pageviews within a one-day window from these events. Moreover, we consider only those hoaxes that survive for at least a week. This leaves us with 1,175 hoaxes.
The complementary cumulative distribution function (CCDF) for the average pageviews an article gets per day is plotted in the following figure. We see that most articles are rarely viewed (median 3 page views per day, and 86% get less than 10 views per day), but a non-negligible fraction of hoaxes get significant traffic. For instance, 1% of the hoaxes that survive for a week get at least 100 page views per day.

References from the web
editFor this part, we measure the number of active links that point to the Wikipedia article. In principle, there could be lots of links to an article, but the ones that matter are the ones that are clicked to get to the article. These could even drive more traffic. We use 5 months of navigation logs to identify the sources of traffic. For each hoax article, we consider the incoming traffic between the time it was created till it was deleted. We also remove traffic driven due to events such as creation, patrolling, flagging and deletion by removing all traffic to the article in a one day window around these events. We categorize the sources into 5 categories: search engine, Wikipedia, social networks (Facebook and Twitter), Reddit and a generic "Other" bucket. We consider all links from search engines as a single link. The CCDF of the number of links to a hoax shows that the distribution is heavily skewed. It has median of 0, and 83.76% have at most one link. However, as with page views, a small fraction of articles (6.8%) have at least 5 in links. We further find that search engines and Wikipedia links themselves are the highest contributors to the actively clicked links to the article (35.3% and 28.5%, respectively) Moreover, "Other" links are also very high (32.8%). These consist of sites such as discussion forums, blogs, etc.
Our analysis shows that hoax articles are accessible via different platforms on the Web. They are also searchable through search engines, making the case even worse.

Analysis of Hoax and Non-Hoax articles
editWe compare four groups of Wikipedia articles in our analysis to understand the differences between them at the time of their creation:
- Successful hoaxes: These articles have passed patrol, are only created once, survive (not suspected of hoax) for at least one month from creation, and are frequently viewed (at least 5 times per day, on average). These hoax articles are impactful, and comprise of 301 hoax articles.
- Failed hoaxes: These are the ones that fail the patrol stage.
- Wrongly flagged articles: These articles were wrongly flagged as hoaxes, as described previously.
- Legitimate articles: These articles are never marked as hoaxes.
As already mentioned, for removing the effect of changing Wikipedia policies over time, for each successful hoax, we consider another articles from each of the other three categories that are created around the same time. This gives us a fair comparison.
We analyse the differences between the articles in terms of four different categories of features:
- Appearance features
- Link network features
- Support features
- Editor features
We describe the details and findings for each of these in the following subsections.
Appearance features
editThese are attributes that a reader would immediately see when viewing the article. These include
- Plain-text length: the number of content words after stripping the Wiki markup. This contains the length of the actual content in the article.
- Plain-text-to-markup ratio: this quantifies the amount of Wiki markup there is in the article. The higher the ratio, the lesser the amount of Wiki markup in the article.
- Wiki-link density: this is the number of Wikipedia links in the article per 100 words.
- Web link density: this is the number of web links in the article per 100 words.
We find striking differences between the different type of articles across these various features.
-
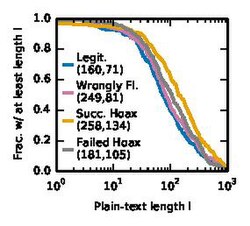 Plain-text length
Plain-text length -
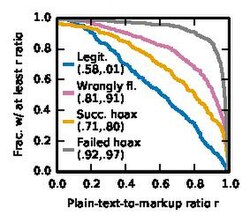 Plain-text-to-markup ratio
Plain-text-to-markup ratio -
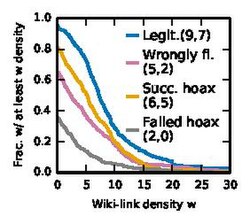 Wiki-link density
Wiki-link density -
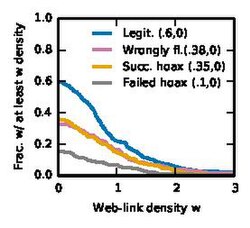 Web-link density
Web-link density




These figures show the complementary cumulative distribution function (CCDF) for the Appearance features. For each, the mean and median are shown in brackets.
We see that although all the articles have similar content length distribution when created, failed hoax articles have very high plain-text-to-markup ratio. This means that hoax articles that do not pass the patrol phase have little-to-no Wikipedia markup. These are followed by wrongly flagged articles, which may indicate that the lesser Wiki markup may be one of the reasons that the article was wrongly suspected in the first place. Successful hoaxes and legitimate articles have lower ratio, i.e. they adhere more to the style of Wikipedia articles. This may be one of the reasons why the hoax was successful, even though it is fake.
We see similar trends for the Wiki and Web-link densities. Legitimate articles have more links, while failed hoaxes have the least. Successful hoaxes and Wrongly flagged articles lie in the middle.
Link Network features
editThis feature dives deeper than the superficial appearance features. The Wiki-links between articles create a network between them. We use this network created by the Wiki-links mentioned in the article at the time of creation, as follows:
- Ego-network clustering coefficient: This is a measure that looks at not only the links originating from an article, but also the connections between the linked articles themselves. For each article, we create an undirected network comprising of the article, the articles that it links and the links between them. The clustering coefficient of the article in question then indicates the coherence of the Wikipedia articles that it links. The higher the clustering coefficient, the more connections there are between these articles, and the more coherent they are.

This figure shows how the clustering coefficient differs between the successful hoax and the legitimate articles, binned into the number of wiki-links that the article has. Intuitively, the more wiki-links an article has, the less likely they are to be connected strongly to each other. So as we see, there is a negative trend in clustering coefficient with the increase in the wiki-outdegree of the article. However, it is important to see that hoax article consistently have significantly lower clustering coefficient than the legitimate articles. This shows that legitimate articles have more coherent Wiki-links in their text as compared to the hoax articles.
Support features
editSupport features measure the extent to which other Wikipedia articles mention the article in question. Intuitively, since hoax articles are fake, they should never be referenced from other Wikipedia articles even before they are created, while legitimate articles should have higher number of mentions. Based on this intuition, we create a set of features to capture this phenomenon:
- Number of prior mentions: This counts the number of times other Wikipedia articles contains the article title, prior to the article's creation. This includes Wiki-link references (these would be red links since the article does not exist yet), and also as text in the article. To find these, we processed Wikipedia's entire revision history. Since searching only for the article title is quite naive, we would count false positives, but it should be similar across the various categories of articles.
- Time of first mention: We measure the time between the article's title first appears in the text and the time the article was created. The intuition behind this is that smart hoaxsters may introduce the mentions for the article prior to creating the article to increase its genuinity, but these should be more recent as compared to genuine mentions already present for the article on Wikipedia.
- Creator of first mention: As we stated, the mention may be created by the hoaxster himself, so we investigate at who inserted the mention text into Wikipedia. These can be the article creator or an IP address.
-
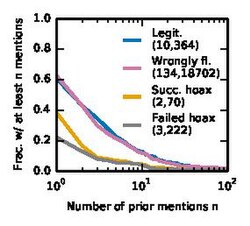 Prior mentions
Prior mentions -
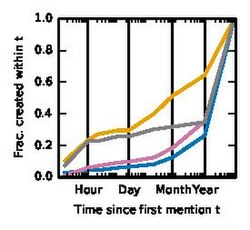 First prior mention creation time
First prior mention creation time -
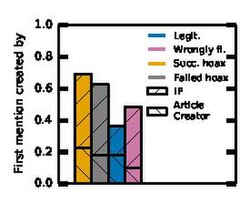 First prior mention creator
First prior mention creator



These figures show that non-hoax articles (legitimate and wrongly flagged) have more mentions prior to their creation as compared to the hoax articles (successful as well as failed). Also, we see that among the ones that have prior mentions, hoax articles' mentions are inserted more recently compared to non-hoaxes. This accounts for the smart hoaxsters who plant the seed prior to creation. Moreover, when we look at who inserted the mention into other Wikipedia articles, we find that hoaxsters use a different account (an IP address) to insert the mention more frequently than for the non-hoax articles, while the fraction of mentions inserted by the article creator is similar. This shows that these hoaxsters are smart and use caution while creating the mention.
Editor features
editFinally, we look at the features from the creator of the article himself. We hypothesize that hoax articles are created by less experienced and newly registered accounts. To test this, we consider the following features:
- Number of prior edits: This quantifies the experience that the creator. We count the number of edits done by the user prior to creating the article.
- Editor's age: This is the time elapsed since the article creator registered the account till the time the article was created.
-
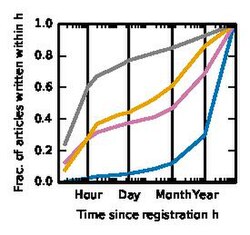 Time since registration
Time since registration -
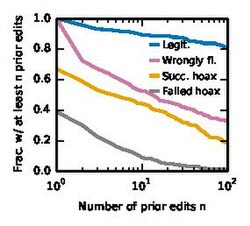 Editor's experience
Editor's experience


These two figures show that our hypotheses were correct. Hoaxsters are indeed newly registered accounts with lesser experience compared to legitimate articles.
Automatic hoax detection
editNext, we build machine-learned classifiers based on the above features to automate the decisions made at various stages of a hoax's life. We consider the following tasks:
- Will a hoax get past patrol?
- How long will a hoax survive?
- Is an article a hoax?
- Is an article flagged as such really a hoax?
The first two are important from a hoaxster's perspective, to understand what makes the hoax survive for long, while the next two tasks are important from maintaining the integrity of Wikipedia. It helps make accurate decisions during and after patrol.
Classifier, features and evaluation
editWe use Random Forest classifier for all our classification tasks. We experimented with other classification techniques, such as Support Vector Machines and Logistic Regression, and found that Random forest works the best.
We use all the features described above as the set of features in the classification tasks.
We evaluate the performance of our classifier in terms of area under the receiver operator characteristic curve (AUC) and accuracy. The baseline values for both these are 50% for all our tasks because we use balanced datasets.
For the classification tasks, we find the importance of the different feature sets using forward feature selection. This technique selects the feature set that improves the performance on the training set the most at each step.
Will a hoax get past patrol?
editIn this task we consider whether the hoax will be able to trick the patroller into believing that the article is a legitimate article. For this task, we take all hoaxes that pass the patrol and randomly select hoaxes that fail the patrol such that they are created on the same day.
The classifier performs reasonably well, and gets an AUC of 71% and accuracy of 66%. The following figure shows the importance of the different set of features , built incrementally using forward feature selection. We find that Appearance features are the most important in this phase, indicating that well written Wiki-like articles are more likely to get past the patrol phase, even for hoax articles.

How long will a hoax survive?
editIn this task is to determine the duration a hoax will survive after passing the patrol. So we split the set of passed hoax articles into various categories depending on the time they survive. We vary with different values of the split. As seen in the figure, whether a hoax will survive for a day or not is easier than deciding for other time splits. This shows that there is a more explicit difference among the hoaxes that survive for at least a day after patrol than the ones that do not.

Is an article a hoax?
editThis step aims to simulate the "flagging" step in detection of the hoax. The positive examples in this case are the hoax articles that pass the patrol. But the most detrimental ones are the ones that survive for long and gain significant traffic. So we focus on the set of successful hoaxes (301 articles) and randomly select legitimate hoaxes created on the same day.
In this task, the classifier performs surprisingly well. The AUC is close to 98% and accuracy is 92%. Therefore, this shows that it is comparatively easier to identify hoaxes once they have survived for a significant amount of time. During feature analysis, we find that Editor features are the most important ones. As we had seen, hoax articles are created by lesser experienced and younger editors. From the high performance of the classifier, we could conclude that these are give-away features in separating the successful hoax from a legitimate article.

Is an article marked as such really a hoax?
editIn this step, we verify whether an article that is flagged as a hoax really a hoax or not. This serves as a safeguard between the "flagging" and "deletion" steps of the article's lifecycle. We consider the set of wrongly flagged articles, and randomly select hoax articles that were created during the same day and that took similar time to get flagged. The classifier has 86% AUC score and 76% accuracy. Again, editor features are the most important.

Human Guessing Experiment
editWe want to understand the factors that give away a hoax to a human. This helps in distinguishing really smart hoaxes versus the ones that only survive for a long time because no one looked at them, or whether the hoax would be able to fool a trained eye such as a patroller. So, we design a crowdsourced evaluation task for humans to identify hoax from a non-hoax, while not being allowed to use external sources for this decision.
We select hoax articles that are publicly available from Speedy deletion wiki [4] from the set of successful hoaxes. This gives us 64 articles. We create an equally sized legitimate article set such that i) for each hoax article there is a legitimate article created on the same day, and ii) the two sets have identical distributions in terms of appearance features. We do this via propensity score matching as before.
We then create 320 random haox/non-hoax pairs by pairing each hoax with 5 non-hoax and vice versa. We showed these pairs to users on Amazon Mechanical Turk, where the task is to identify hoax from non-hoax only by looking at the text and not searching elsewhere.
Human vs classifier accuracy
editWe find that humans have 66% accuracy on all rated pairs. The random guessing accuracy is 50%. When we use our hoax vs legitimate classifier on this task, we get an accuracy of 86%, thus outperforming humans by a large margin.
Since the humans only see the appearance features, we use a human-vs-legitimate classifier trained only on those features for classification, and we obtain an accuracy of 47%. This roughly random behavior is expected because the set of hoax and non-hoax articles were created to have very similar distributions with respect to the appearance features, so these features are uninformative in the task.
Thus only looking at the looks of the article can be very misleading and more intricate features that look under the surface are needed -- network, support and editor features -- to accurately identify the hoax from non-hoax.
Human bias
editTo understand the factors that humans use to judge articles, we calculate the within-pair difference δ of feature f for the suspected hoax minus the suspected non-hoax for each pair shown to humans. If δ is smaller than 0, then it means that humans tend to think that lower values of f implies hoax. We also calculate the within-pair difference δ* of the same feature f for the actual hoax minus the actual non-hoax.
We show some of these biases using boxplots below. For the first one, when taking the logarithmic number of all words as f, we see that δ is lower than zero while δ* is very close to zero. This means that even though in our dataset there is no bias in terms of the length of the article, humans tend to believe that shorter articles are hoaxes. Similarly, when we look at the plain-text-to-markup ratio, we find that humans believe that articles with higher ratio, i.e. lesser Wiki markup, are hoaxes, while this is less pronounced for the real hoax and non-hoaxes.
-
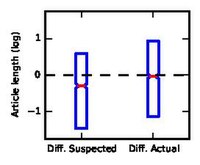 Human bias towards article length
Human bias towards article length -
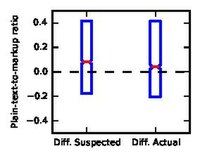 Human bias towards plain-text-to-markup ratio
Human bias towards plain-text-to-markup ratio


Easy vs hard hoaxes
editNext we want to understand the attributes that make a hoax hard to detect. For this we compare the within-pair difference of feature for easy hoaxes and hard hoaxes. To define the set of easy and hard hoaxes, we first rank the hoaxes in increasing order of their rate at which humans identified them correctly. The upper third are easy, and the lower third are the hard hoaxes.
We find that hoaxes that are longer, have more Wiki links and have lower plain-text-to-markup ratio (i.e. more Wiki markup) are harder to identify. For instance, the median logarithmic number of plain-text words of the hard group is higher by about 1 than the easier ones, so hard-to-recognize hoaxes are 2.7 times longer than easy-to-recognize hoaxes.
-
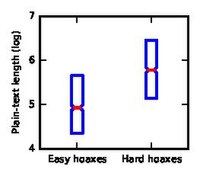 Plain-text length
Plain-text length -
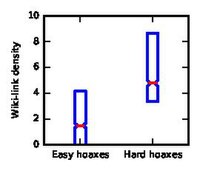 Wiki-link density
Wiki-link density -
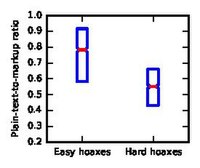 Plain-text-to-markup ratio
Plain-text-to-markup ratio



Trawling Wikipedia for hoaxes
editWe are running our classifier on the entire English Wikipedia revision history. So far, our algorithm has found the following hoax articles:
- Steve Moertel: DELETED. The article was about an alleged popcorn entrepreneur. This article survived for 6 years 11 months, making it one of the longest running hoaxes!
- Maurice Foxell: DELETED. The article was about an alleged children’s book author and Knight Commander of the Royal Victorian Order. This article survived for 1 year 7 months.
Research Publication and Presentation
editThe research paper with complete details are present at http://cs.umd.edu/~srijan/pubs/hoax-www16.pdf.
Slides for the research presentation at the conference are present at http://cs.umd.edu/~srijan/slides/hoax-www16.pptx.
Talks
editThis research will/has been presented at multiple venues:
- Research paper presentation at World Wide Web (WWW) conference, April 2016, Montreal, Canada.
- Invited talk at CyberSafety workshop, Conference on Information and Knowledge Management (CIKM), October 2016, Indianapolis, USA.
- Part of tutorial at International conference on Advances in Social Network Analysis and Mining (ASONAM), August 2016, San Francisco, USA.
- Part of tutorial at World Wide Web (WWW) conference, April 2017, Perth, Australia.
- Invited talk at VOGIN-IP conference, March 2017, Amsterdam, Netherlands.