Research:New user reading patterns
The goal of this work is to understand the factors involved in user-account creation on wikipedia.
The main findings of this analysis are:
- Using webrequest logs, we build a method that allows to identify and characterize the reading patterns of approx. 80% of users that register a new account across wiki with different languages.
- New users visit the [en:Special:RecentChanges] much more often than 'normal' users who do not register. The fraction of those users varies from 1% (enwiki) to 8% (kowiki, desktop-acces).
- New users preferentially register via desktop-access: ~70% (in comparison, non-registration reading sessions have only ~30% desktop-access).
- in comparison to the amount of overall traffic, users from Asia and Africa have a much higher rate to register for an account
- New users start their reading session (before the registration) much more often in a namespace different to the article-ns (0), in particular 4 (Wikipedia) and 12 (Help)
- Reading sessions of new users tend to be longer (even when considering the part before registration) than for non-registration users.
Motivation
editWhile it is possible to edit Wikipedia without an account, many editors choose to use a dedicated account for their contributions. Therefore, understanding motivations and experiences of newly-registered users provides important insights into the processes underlying the transformation from reader to contributor in wikipedia. This in turn could help identify ways in which to improve new user's experience in wikipedia projects.
Related work
editThere has been done much work in the "Understanding first day" project ( EditorJourney ) to characterize workflows of new editors:
Most new users who create accounts do not ever make edits -- but those who do make edits usually make them on their first day of having an account. We have little knowledge of what new account holders do on that first day after they create their accounts -- whether they read help content, attempt edits that they do not publish, or something else.
Similarly, large efforts have been devoted to Characterizing reader behaviour in order to understand the information needs of readers.
Here, we try to characterize the context in which readers choose to become (potential) contributors.
Methodology
editWe use the standard webrequest logs to identify [Reader sessions].
For the data-query from webrequest logs we set the following parameters:
- 1 week (2019-09-09 -- 2019-09-16)
- English Wikipedia ('normalized_host.project_family'=='wikipedia', 'normalized_host.project'== 'en')
- mobile and desktop version ('access_method'=='mobile web'/'desktop')
- Sessions are cut into subsessions with threshold of 60 minutes (see previous work)
Identifying new users
editIn order to identify new users we check the following criteria
- visit to the Create Account page (via 'uri_query')
- in order to assess whether an account was created we check whether the logged_in-status changed from 0 to 1 after the visit to the account creation (via x-analytics)
| Spark query to identify new users |
|---|
import os, sys
import numpy as np
import datetime
from pyspark.sql import functions as F, types as T, Window
import calendar
import pandas as pd
## define time frame
date_start = datetime.datetime(2019, 9, 9, 0)
date_end = datetime.datetime(2019, 9, 16, 0)
ts_start = calendar.timegm(date_start.timetuple())
ts_end = calendar.timegm(date_end.timetuple())
row_timestamp = F.unix_timestamp(F.concat(
F.col('year'), F.lit('-'), F.col('month'), F.lit('-'), F.col('day'),
F.lit(' '), F.col('hour'), F.lit(':00:00')))
## hash for user-fingerprinting
user_id = F.hash(F.concat(F.col('client_ip'),F.lit('-'),F.col('user_agent'))) ## only client and user
page_create_account = F.when(F.col('uri_query').contains('Special:CreateAccount'),1).otherwise(0)
w = Window.partitionBy(F.col('user_id'))
w_user_ts = Window.partitionBy(F.col('user_id')).orderBy(F.col('ts'))
# maximum number of requests per session of an individual
n_p_max = 500
n_p_min = 1
##choice see here: https://meta.wikimedia.org/wiki/Research:Characterizing_Wikipedia_Reader_Behaviour/Code
## dataframe with all webrequest of all users that visited at least once a createaccount page
df = (
## select table
spark.read.table('wmf.webrequest')
####Define some extra-columns
## user-hash as user_id
.withColumn('user_id',user_id)
## shortcut for page-title
.withColumn('page_title', F.col('pageview_info.page_title') )
## logged_in 0/1
.withColumn('logged_in', F.coalesce(F.col('x_analytics_map.loggedIn'),F.lit(0)) )
## page create account
# .withColumn('page_create_account',F.coalesce(F.col('page_title')=='Special:CreateAccount', F.lit(0)) )
.withColumn('page_create_account',page_create_account)
## select time partition via windows
.where(row_timestamp >= ts_start)
.where(row_timestamp < ts_end)
# ## select wiki project
.where( F.col('normalized_host.project_family') == "wikipedia" )
.where( F.col('normalized_host.project') == "en" )
## only requests marked as pageviews
## note that special-pages are not recorded as pageviews anymore
## https://phabricator.wikimedia.org/T234188#5580465
.where( (F.col('is_pageview') == 1) |
(F.col('uri_query').contains('title=Special:CreateAccount'))
)
## agent-type
# .where( F.col('agent_type') == "user" )
## user: desktop/mobile/mobile app; isaac filters != mobile app
.where( F.col('access_method') != "mobile app" )
## unclear yet; done by isaac
.where( F.col('webrequest_source') == 'text' )
## count requests per user
## n_pca_by_user: number of requests to page-create-account
## n_p_by_user: number of requests to pages
.withColumn('n_pca_by_user', F.max( F.col('page_create_account') ).over(w) )
.withColumn('n_p_by_user', F.sum(F.col('is_pageview').cast("long")).over(w) )
## filter:
## ## user rquested at least 1 page view for create account
.where(F.col('n_pca_by_user') == 1 )
## ## user requested at most n_p_max pages in total
.where(F.col('n_p_by_user') >= n_p_min)
.where(F.col('n_p_by_user') <= n_p_max)
.orderBy('user_id','ts')
## records logged-in state of next page-visit
.withColumn('logged_in_next', F.coalesce(F.lead('logged_in',1).over(w_user_ts), F.lit(0)))
## record registration event
## ## 1) visit the 'Special:CreateAccount' page
## ## 2) not being logged in when making that request
## ## 3) being logged in when visiting the next page
.withColumn('event_register',
F.when( (F.col('logged_in') == 0) &
(F.col('logged_in_next') == 1) &
(F.col('page_create_account')==1),1
).otherwise(0)
)
## record if request belongs to a session where a registration event occured
.withColumn('new_user_session', F.max(F.col('event_register')).over(w))
# filter new-user-session requests
.where(F.col('new_user_session')==1)
.select('user_id',
'ts',
'logged_in',
'event_register',
'is_pageview',
'page_title',
'page_id',
'namespace_id',
'access_method',
'agent_type',
'normalized_host',
'referer',
'uri_query',
F.col('geocoded_data.continent').alias('continent'),
)
)
## obtain result as pandas dataframe
df = df.toPandas()
## save output
filename = os.path.join('output','df_reading-sessions_new-users_v5_%s-%s-%s-%s_%s-%s-%s-%s.csv'\
%(date_start.year,date_start.month,date_start.day,date_start.hour,
date_end.year,date_end.month,date_end.day,date_end.hour))
df.to_csv(filename)
|
| Cutting sessions with activity threshold |
|---|
'''
cut reading sessions if time between two consecutive requests is larger than delta_t.
a common choice is delta_t=1 hour [1]
[1] Halfaker, et al. (2015).
User Session Identification Based on Strong Regularities in Inter-activity Time.
Proceedings of the 24th International Conference on World Wide Web, 410–418.
'''
import pandas as pd
from datetime import datetime
from datetime import timedelta
def cut_subsessions(df, delta_t_cut = 3600):
'''
df is a dataframe with columns:
- user_id (a hash from fingerprinting)
- ts, a timestamp
returns dataframe where user_id gets replaced by
- 'user_id-<subsession>', with subsessions = 0,1,2,3,4,...
'''
df = df.sort_values(['user_id','ts'])
#### Delta-t between logs
df_tmp = df.copy()[['user_id','ts']]
## transform timestamp into datetime
df_tmp['ts'] = df_tmp['ts'].apply(lambda x: datetime.strptime(x, "%Y-%m-%d %H:%M:%S"))
## calculate timedifference to previous log (if from same user)
df_tmp['delta_dt'] = df_tmp['ts'] - df_tmp['ts'].shift()[df['user_id'] == df_tmp['user_id'].shift()]
## dt =0 for first log of user (there is no previous by definition)
df_tmp['delta_dt'] = df_tmp['delta_dt'].fillna(pd.tslib.Timedelta(seconds=0))
## transform into seconds
df_tmp['delta_sec'] = df_tmp['delta_dt'].apply(lambda x: x.seconds)
#### Identify cut points
## put a 1 in each log that starts a new session
df_tmp['cut'] = 1*(df_tmp['delta_sec']>delta_t_cut)
## cumsum (within a user) to enumerate sessions of same user (0,1,2,...)
df_tmp['cut_cumsum'] = df_tmp.groupby('user_id')['cut'].apply(lambda x: x.cumsum())
## append session-index to user_id to get new user_id
df_tmp['user_id_cut'] = df_tmp.apply(lambda x: str(x['user_id'])+'-'+str(x['cut_cumsum']),axis=1)
df['user_id'] = df_tmp['user_id_cut']
return df
date_start = datetime(2019, 9, 9, 0)
date_end = datetime(2019, 9, 16, 0)
## first get number of events from the new registrations
filename = os.path.join('output','df_reading-sessions_new-users_v5_%s-%s-%s-%s_%s-%s-%s-%s.csv'\
%(date_start.year,date_start.month,date_start.day,date_start.hour,
date_end.year,date_end.month,date_end.day,date_end.hour))
df = pd.read_csv(filename,index_col = 0)
df = cut_subsessions(df)
## filter only those that contain registration event
df_user = pd.DataFrame()
df_user['event_register'] = df.groupby('user_id')['event_register'].max()
df['filter'] = df['user_id'].apply(lambda x: df_user['event_register'][x])
df = df[df['filter']==1]
df = df.drop('filter',axis=1)
## first get number of events from the new registrations
filename_save = filename[:-4]+'_filtered.csv'
df.to_csv(filename_save)
|
Identifying non-new users
editIn order to put numbers obtained from the analysis of newly registered users in context, we would like to compare with reading sessions that do not lead to the creation of a new account. Naturally, this number is much larger. Therefore, we obtain a smaller subsample with an approximately similar number of observations from the same time period. Specifically, we select the subsample of sessions in which the user was not logged-in during the entire session.
Due to the size of the data, we query a given number of samples per day from the webrequest log in order to avoid the following error in the join
Py4JJavaError: An error occurred while calling o146.collectToPython.
- java.util.concurrent.TimeoutException: Futures timed out after [300 seconds]
| Spark query for subsample of 'normal' users |
|---|
import os, sys
import numpy as np
import datetime
from pyspark.sql import functions as F, types as T, Window
import calendar
import time
import pandas as pd
date_start = datetime.datetime(2019, 9, 9, 0)
date_end = datetime.datetime(2019, 9, 16, 0)
year = date_start.year
month = date_start.month
day1 = date_start.day
day2 = date_end.day
list_days = range(day1,day2,1)
N_sample = 5000 ## number of samples per day
# hash for user-fingerprinting
user_id = F.hash(F.concat(F.col('client_ip'),F.lit('-'),F.col('user_agent'))) ## only client and user
w = Window.partitionBy(F.col('user_id'))
# minimum/maximum number of pageviews
n_p_max = 500
n_p_min = 1
##choice see here: https://meta.wikimedia.org/wiki/Research:Characterizing_Wikipedia_Reader_Behaviour/Code
## dataframe with all webrequest of all users that visited at least once a createaccount page
for day in list_days:
print(day)
spark.sql('SET spark.sql.shuffle.partitions = 1024')
df = (
## select table
spark.read.table('wmf.webrequest')
####Define some extra-columns
## user-hash as user_id
.withColumn('user_id',user_id)
## shortcut for page-title
.withColumn('page_title', F.col('pageview_info.page_title') )
## logged_in 0/1
.withColumn('logged_in', F.coalesce(F.col('x_analytics_map.loggedIn'),F.lit(0)) )
## select time partition via windows
# .where(row_timestamp >= ts_start)
# .where(row_timestamp < ts_end)
.where( F.col('year')==year )
.where( F.col('month')==month )
.where( F.col('day')==day )
# .where( F.col('hour')==hour )
# ## select wiki project
.where( F.col('normalized_host.project_family') == "wikipedia" )
.where( F.col('normalized_host.project') == "en" )
## only requests marked as pageviews
.where( F.col('is_pageview') == 1 )
## agent-type
.where( F.col('agent_type') == "user" )
## user: desktop/mobile/mobile app; isaac filters != mobile app
.where( F.col('access_method') != "mobile app" )
## unclear yet; done by isaac
.where( F.col('webrequest_source') == 'text' )
#### remove users who exceed a threshold in number of pageviews in time-period
## n_p_by_user: number of requests to pages
.withColumn('n_p_by_user', F.sum(F.col('is_pageview').cast("long")).over(w) )
## ## user requested at most n_p_max pages in total
.where( F.col('n_p_by_user') >= n_p_min )
.where( F.col('n_p_by_user') <= n_p_max )
#### remove users who were loggedin at some point in their session
## whether there was a login somewhere along the session
.withColumn('n_p_loggedin_by_user', F.max( F.col('logged_in') ).over(w) )
# ## only users that were never logged in
.where( F.col('n_p_loggedin_by_user') == 0 )
# .orderBy('user_id','ts') ## this might not be needed here
# .
.select('user_id',
'ts',
'logged_in',
'is_pageview',
'page_title',
'page_id',
'namespace_id',
'access_method',
'agent_type',
'normalized_host',
'referer',
'uri_query',
F.col('geocoded_data.continent').alias('continent'),
)
)
## non-random sampling
df_users_sample = df.select('user_id').distinct().limit(N_sample)
## join
df_sample = df.join(df_users_sample, df['user_id'] == df_users_sample['user_id'] , "left_semi" )
df_sample = df_sample.toPandas()
filename = os.path.join('output','df_reading-sessions_all-users_v5.1-by-day_tmp_%s-%s-%s_N%s.csv'\
%(year,month,day,
N_sample))
df_sample.to_csv(filename)
## stitch together the individual files
df = pd.DataFrame()
for day in list_days:
filename = os.path.join('output','df_reading-sessions_all-users_v5.1-by-day_tmp_%s-%s-%s_N%s.csv'\
%(year,month,day,
N_sample))
df_tmp = pd.read_csv(filename,index_col = 0)
print(len(df_tmp))
df = df.append(df_tmp)
df = df.sort_values(by=['user_id','ts']) ## order by users and time
df.index = range(len(df)) ## define new index from 0 ... len df
filename = os.path.join('output','df_reading-sessions_all-users_v5_%s-%s-%s-%s_%s-%s-%s-%s_N-per-day%s.csv'\
%(date_start.year,date_start.month,date_start.day,date_start.hour,
date_end.year,date_end.month,date_end.day,date_end.hour,
N_sample))
df.to_csv(filename)
|
Similarly, we then have to use activity thresholds to cut sessions into subsessions.
| Cutting sessions with activity threshold |
|---|
import os, sys
import numpy as np
import datetime
# from pyspark.sql import functions as F, types as T, Window
import calendar
import time
import pandas as pd
from datetime import datetime
from datetime import timedelta
date_start = datetime(2019, 9, 9, 0)
date_end = datetime(2019, 9, 16, 0)
N_sample = 5000
filename = os.path.join('output','df_reading-sessions_all-users_v5_%s-%s-%s-%s_%s-%s-%s-%s_N-per-day%s.csv'\
%(date_start.year,date_start.month,date_start.day,date_start.hour,
date_end.year,date_end.month,date_end.day,date_end.hour,
N_sample))
df = pd.read_csv(filename,index_col = 0)
df = cut_subsessions(df)
## first get number of events from the new registrations
filename_save = filename[:-4]+'_filtered.csv'
df.to_csv(filename_save)
|
Results
editThe methodology described above identifies 24,909 sessions during which an account was created.
Assessing reliability
editHow reliable is our approach to identify account-creation events from webrequest logs?
We compare the number of new users with data from Mediawiki_user_history (created_by_self==True) based on hourly windows over the 1-week period.
We systematically underestimate the number of new users (roughly 80%). Nevertheless, the ratio is surprisingly stable (the variations across time are much larger) indicating that we can identify at least a fraction of new users via webrequests. Overall, this can be seen as indirect evidence for the robustness of our approach.


Entry via 'Special:Recent_changes
editOne hypothesis emerging from discussions with, e.g. the Growth-team, is that users decide are motivated to register after visiting Recent changes. We therefore assess the fraction of users that visited a this page (for new users only before the registration).
We find that approximately 1% of new users visited the Recent-changes page. This number is very similar for desktop and mobile (no errorbars shown here). While this number is not very large in absolute terms, it is order of magnitude higher than for users that do not register (in fact, we count exactly 1 such occurrence in the latter situation).

Desktop vs mobile
editIn view of how to improve the user experience, it is interesting to see whether new users use the desktop or mobile version.
We find that the number of new users from desktop access is about 50% larger than for mobile acess. Surprisingly, when looking at non-registered users, this is essentially reversed -- i.e. the fraction of users accessing from mobile is much larger.

Geographic origin
editIn order to assess possible gaps in accessibility, it is interesting to quantify geographic location (on the level of continent) of new users.
North America and Asia have the most number of new users. While the absolute number of new users are similar, the interpretation changes when comparing with the absolute numbers of all users. The fraction of 'normal' traffic is much higher from North America than from Asia. This means that the fraction of users who create a new account (of the overall traffic) is much larger for users from Asia and much smaller for users from North America. Similar are the cases of Africa (former) and Europe (latter).

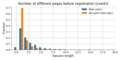
Length of session
editThe length of the reading sessions differs for users that create an account and users that do not create an account. Specifically, reading sessions defined as the number of different pages (is_pageview==1) has a much longer tail for new users, i.e. the sessions tend to be longer. Interestingly, when only considering the length of the session before the account was created, the difference becomes much smaller.


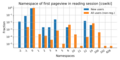
Namespaces
editIn order to understand the information need, we considered the namespace of the first page-view in the reading session (note that we assign namespace=-2 if we cannot identify a namespace, for example if the reading session started with the account-creation).
While namespace 0 (main/article) covers the majority of the cases, it is slightly smaller for users that create an account. When looking at the log-scale, we can see the differences in the other namespace-categories with a much smaller contribution. In particular, we see that new users start much more often the following namespaces: -1 (Special), 4 (Wikipedia), 12 (Help), and 14 (Category). Also namespaces 1 (article talk), 2 (user), and 3 (user talk) are worth to mention. Note that these differences are not due to different usage of mobile vs desktop access (not shown here).


Topics
editIn order to understand the information need of new users that create an account, we would like to get an idea of the topics of the visited pages. Assigning topics to articles in Wikipedia is a non-trivial problem. Here, we use the topic model. The advantage of this approach is that it can be applied to articles of any language. More specifically, it is motivated by the categories defined in the ORES Draft topic model and instead of the text (in the English version article) uses the statements in the corresponding Wikidata-item (see work-log) taking advantage of the mapping of Wikipedia articles in different languages and Wikidata items (see [1]).
Here, we look at the topic of the first visited page in reading sessions of new users. Comparing users that register with users that do not, we find the following differences:
- Culture.Language_and_literature is much more common for users that register
- Person is much higher for users that do not register
- STEM.Technology is slightly higher for users that register

We focus on namespace 0 (Main/Article); for the other namespaces, we i) cannot assign topics with high confidence for a large fraction of pages (we label this case as '-2'), and ii) the topic distribution is highly skewed towards 'Culture.Language_and_literature' which seems to be an artifact of the algorithm. See an example for the namespace 12 (Help)

Other languages
editWith few exceptions we find very similar patterns when looking at wikis with different languages (and thus different sizes). For this we aim to run the analysis for the following languages:
- German (Create Account page - de)
- French (Create Account page - fr)
- Arabic (Create Account page - ar)
- Czech (Create Account page - cz)
- Korean (Create Account page - ko)
Since the number of events for most of these wikis is much smaller, we consider data from a longer time-window (2019-09-01 -- 2019-09-30).
Reliability
editWhile the absolute number of new user registrations varies, we consistently capture approx. 80% of the new user registrations when comparing webrequest logs with the number of registration events in mediawiki-history. The only exception is kowiki, for which this number drops to approx. 60%.
-
 enwiki
enwiki -
 dewiki
dewiki -
 frwiki
frwiki -
 arwiki
arwiki -
 swiki
swiki -
 kowiki
kowiki






Recent changes
editInterestingly, enwiki is an exception here: i) the fraction of users who visit the 'Recent-changes' page is lowest (around 1%) nad ii) there is little difference between desktop and mobile. In other language-wikis, the recent-changes visits is substantially larger (in kowiki up to 8x larger). In addition, desktop and mobile access is very different in that for desktop-access the fraction is much larger.

Mobile vs Desktop
editAccess of new and all users is very similar across all language-wikis. For new users, the majority (~70%) accesses via desktop. In contrast, for users that do not register, the majority comes from mobile (desktop drops to ~30%). Interestingly, for arwiki the desktop access is lower for all cases compared to the other wikis.

Geographic origin
editObservations regarding the access from different continents:
- enwiki: number of new registrations much larger for Asia and Africa when compared to traffic from non-registered users (see above for more details)
- dewiki: almost all access from Europe
- frwiki: some access from Africa and North America. Simlarly to enwiki, the rate of new user registration from Africa is higher than what one would expect from amount of traffic of non-registered users.
- arwiki: most access from Asia and Africa
- cswiki: most access from Europe
- kowiki: most access from Asia
-
 enwiki
enwiki -
 dewiki
dewiki -
 frwiki
frwiki -
 arwiki
arwiki -
 cswiki
cswiki -
 kowiki
kowiki






Length of sessions
editLength of reading sessions are very< similar across languages.
-
 enwiki
enwiki -
 dewiki
dewiki -
 frwiki
frwiki -
 arwiki
arwiki -
 cswiki
cswiki -
 kowiki
kowiki






Namespaces
editAcross wikis, new users visit the article-namespace (0) slightly less often as a starting namespace (even though it still constitutes the majority of cases). Instead, new users have a higher chance to start the session in a non-article namespace. The most common cases are:
- 4 (Wikipedia)
- 12 (Help)
-
 enwiki
enwiki -
 dewiki
dewiki -
 frwiki
frwiki -
 arwiki
arwiki -
 cswiki
cswiki -
 kowiki
kowiki





