Research:Mobile sessions
Session length identification is a necessary prerequisite for many pieces of useful analysis and research, such as read times and page request frequency, that inform the software the Wikimedia Foundation develops. Using the Mobile logs of page requests, and a unique fingerprint composed of the user-specific data stored within it, this project performs an inter-time analysis of user reading activity to identify probable session length.
Performing that analysis on a sample from 23-30 January 2014, we find a median session time of 268 seconds, with a mean session time of 444.42 seconds. This exclusively covers users with more than one page request, since inter-time analysis requires multiple events.
Introduction
editThe role of Mobile
edit
Mobile devices are an increasingly important way for internet users to consume web content. In 2012, mobile devices were responsible for over 10 percent of web requests;[1] in 2013, this increased to 17.4%.[2] Many organisations, including the Wikimedia Foundation, have been investing resources in capitalising on this and developing effective mobile websites and applications. In the Wikimedia Foundation's case this comes in the form of threee efforts - one, on the part of the Mobile Web team, to design an efficient website for direct browsing (m.[wikimedia site].org), a second to design an efficient set of mobile applications for Android and iOS operating systems, and the Wikipedia Zero programme which negotiates with mobile phone carriers to grant free (zero-rated) access to Wikipedia for their users. These groups produce products in heavy usage, and the mobile teams - specifically, Web and Apps - are seeking more data on how people are using their software.
Session length analysis
editThe specific question Mobile would like answered is what session lengths look like for Mobile users. This is being asked from a Product point of view, but it's also an interesting question for researchers - not because it produces results that are prima facie interesting (although it can be a useful comparator to, say, desktop session length), but because it enables further research. A lot of user behaviour analysis is dependent on being able to accurately reconstruct sessions, and a variety of papers have been published on the subject, mostly focusing on user behaviour around search engines and data retrieval from them.[3][4][5][6] There is also one paper that directly refers to sessions in the context of Wikipedia and other CSCW communities, albeit one dealing with editors rather than readers.[7] While many of these papers are not directly useful (their methodology, for example, is largely dependent on resources not available with Wikimedia web properties), the intended applications of their research are. Session identification and analysis can be used to answer a variety of interesting questions around the behaviour of readers and other passive participants, such as read times, topic clustering or an understanding of the performance of our linking and searching processes.
Research questions
editThe primary research question can be summarised as:
What does session length look like for our mobile interface?
To answer this, we have to answer several subsidiary questions, namely:
- How do we identify 'unique users'?
- How do we define a session, and how do we identify it?
Dataset
editThe (obviously) standard way of analysing reader behaviour like sessions is through request and transaction logs,[3][4] which records and logs information when an internet user submits a request to a server. Suneetha & Krishnamoorthi (2009)[8] looked at the various types of transaction logs available for web mining, and divided them into three categories, by storage location; server-side logs (logs maintained by the web server that contains the information being requested), proxy-side logs (maintained by machines that handle those requests and pass them to the web server), and client-side logs (logs stored on the computer of the person making the request). They identified server-side logs as the most accurate and complete, but noted two drawbacks; that the logs contain sensitive information, and that the logs do not record cached page visits. The Wikimedia ecosystem's store of reader data is found in the logs of our cacheing servers ('RequestLogs'), which are essentially server-side logs by Suneetha's definition. In addition, they track cached page visits, and the store of sensitive information is useful for identifying unique users, although it requires some restrictions around the dataset.
The structure of the 'RequestLogs' is:
| Column name | Type | Description | Example |
|---|---|---|---|
| hostname | String | The name of the cache server the request is processing through | cp1060.eqiad.wmnet |
| sequence | Integer | The per-host request number. It increases by 1 for each request on that host. | 919939520 |
| dt | String | The date and time of the request, in UTC | 2014-01-03T20:08:27 |
| ip | String | The IP address of the client | 192.168.0.1 |
| time_firstbyte | Floating-point number | The amount of time (in seconds) before the first byte of the requested content was transmitted | 0.001473904 |
| cache_status | String | The cache's response code | hit |
| http_status | Integer | The HTTP status code associated with the request | 200 |
| response_size | Integer | The size of the returned content, in bytes | 87 |
| http_method | String | The HTTP method associated with the request | GET |
| uri_host | String | The site the request was aimed at | meta.m.wikimedia.org |
| uri_path | String | The page the request was aimed at | /wiki/Special:BannerRandom |
| uri_query | String | Any parameters (say, ?action=edit) associated with the request | ?uselang=en&sitename=Wikipedia&project=wikipedia&anonymous=true |
| content_type | String | The MIME type of the returned content | text/html |
| referer | String | The referring page | http://google.com |
| x_forwarded_for | String | The X-Forwarded-For header | - |
| user_agent | String | The user agent of the client | Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:26.0) Gecko/20100101 Firefox/26.0 |
| accept_language | String | The user language (or language variant) | en-US,en;q=0.8 |
| x_analytics | String | An instrumentation field used by the Wikipedia Zero team | - |
These logs provide us with a variety of types of sensitive information for user identification, along with timestamps of page requests. These are available for all hits to the Mobile website, including through Wikipedia Zero, but exclude Mobile Apps.
The RequestLogs contain not just 'intentional' page requests - where a user actively navigates to a particular article or discussion page on Wikipedia - but also automatic or incidental requests for page elements. For example, navigation to the article Barack Obama appears in the RequestLogs not as a single request, but as multiple requests - one for the page, one for each of the images, so on and so forth. In addition, the RequestLogs include logs for page requests that failed due to an error, and were not completed.
What we are looking to do is identify, for each user, what pages they were actually presented with. Without filtering to this, many further research projects in this area, and many ways of understanding sessions themselves, are not available. An example of the first would be a look at read times for each page; an example of the second would be performing inter-time analysis. In both cases, the analysis cannot be performed if the dataset includes, say, page elements or failed requests, which would throw off the data.

The most logical definition of pageview, therefore, is 'a user-intended request for a page on Wikipedia that is completed by the server and delivered to the user'. This excludes:
- Page requests that failed, in line with Burby (2007);[9]
- Requests for incidental page elements.
To perform this filtering, we filtered by http status code (to exclude failed requests) and MIME type (to exclude page elements). A sample of all requests from 10,000 randomly-selected IPs was then taken from the logs on 20 January 2014, to answer research questions 1 and 2. A sample of all requests from 50,000 randomly-selected IPs, between 23 and 30 January 2014, was then taken to answer research question 3.
RQ1: How do we identify 'unique users'?
editWithout an understanding of 'unique users' and a way of individually fingerprinting or identifying them, any attempt to estimate session length is impossible. Much of the existing literature stems from datasets in which a cookie-based unique user identifier was available;[3][4][10] with the RequestLogs, this is not the case. The only sensitive information we have to work with is the IP address, user agent and language preference associated with each request. Suneetha & Krishnamoorthi (2009) discuss the use of IP address as a 'unique' identifier,[8] but that is unlikely to be sufficient for mobile users; the current architecture of mobile telecommunications means that there is a very high user:IP ratio. Suneetha also discusses the use of different user agents as a way of distinguishing multiple users with the same IP address, which is likely to be necessary but is not substantiated in the paper as a method. Accordingly, it seems sensible to use all of the sensitive information available to us - IP address, user agent and user language - as a way of distinguishing users, and then try to validate it by comparing it to dataset in which we do have a cookie-based unique user identifier. Accordingly, our hypothesised 'unique user' definition can be simply expressed in pseudo-code as
IP + UA + lang
We then have two challenges. The first is proving that the inclusion of user agent and language preference in our unique user identifier increases the granularity of the dataset. The second is proving that the resulting identifier, when tested against a dataset with a more traditional unique identifier, is accurate for our purposes. 'Accurate' means that it avoids either 'sharding' a unique client's activity (identifying it as activity from multiple unique clients) or 'grouping' the activity of multiple unique clients (identifying all of the activity as the result of one unique client).
Results
editTesting granularity, we broke the identifier down into its component parts (IP address, user agent and language preference) and ran it over the 10,000 IP sample piece-by-piece, examining how the inclusion of each element increased the number of unique identifiers in the dataset.
| Element | Unique values | Improvement on previous | Improvement on IP |
|---|---|---|---|
| IP address | 9,478 | N/A | N/A |
| IP + User Agent | 20,085 | 111.9% | 111.9% |
| IP + User Agent + language | 20,541 | 2.3% | 116.7% |
The entire identifier produce over twice as much granularity as simply relying on IP address, mostly thanks to the inclusion of the user agent.
Next, we tested whether this granularity was accurate. It is one thing to produce granular unique identifiers - it is another to produce unique identifiers that actually match 'unique users', or 'unique clients'. To test this, we ran the identifier algorithm over a dataset containing a different, cookie-based unique identifier, experimentID - the result of Aaron Halfaker and Ori Livneh's work on testing module storage performance. After retrieving the ModuleStorage dataset for 20 January, we see 38,367 distinct IPs, distributed over 36,918 distinct experimentIds, with 94,444 requests. Almost all of the IPs have only one corresponding experimentId, with the highest being 49 associated with a single IP in the 24-hour period selected (Fig. 2). The inverse of that - how many experimentIds have multiple IPs in that period - sees a similar distribution, with 3,876 users being sharded over multiple IPs (Fig. 3).
-
 Fig. 2: Density plot of the IP-to-user ratio in ModuleStorage data
Fig. 2: Density plot of the IP-to-user ratio in ModuleStorage data -
 Fig. 3: Density plot of the user-to-IP ratio in ModuleStorage data
Fig. 3: Density plot of the user-to-IP ratio in ModuleStorage data


If we run our identifier algorithm over this dataset, restricting the dataset to 'sessions' using Geiger & Halfaker (2013)'s[7] methodology - looking for the time in seconds at which a user, having not made an action, is statistically unlikely to make another one (400-500 seconds - see Fig. 4) - we find a 0.766% effective sharding rate. Conversely - looking at situations where hashing groups multiple 'Unique Clients' that are a single experimentId - we see a 0.969% effective error rate. The algorithm is, for all intents and purposes, accurate - with the caveat that it assumes experimentId generator accuracy over a 400-500 second span.
-
 Fig. 4: ModuleStorage time between each request
Fig. 4: ModuleStorage time between each request -
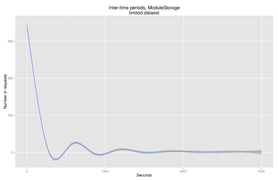 Fig. 5: ModuleStorage time between each request, restricted to entries <3000 seconds
Fig. 5: ModuleStorage time between each request, restricted to entries <3000 seconds


Discussion
editIncluding both user agent and request language in the unique user identifier dramatically increased granularity, compared to merely using IP addresses. Furthermore, comparing this identifier to cookie-based unique identifiers showed that, for the time period we are interested in, it is not substantially less accurate. This result suggests that the unique user identifier of 'IP, user agent and language' is sufficient for fingerprinting users for the purpose of session analysis.
RQ2: How do we define a session, and how do we identify it?
editWithin web-based research and analytics, 'session' is defined in multiple ways. Jansen & Spink (2003) simply define a session as 'the entire series of queries submitted by a user during one interaction with [the website]", without actually defining what an 'interaction' is.[3] Arlitt (200)[11] defines it similarly, identifying a session as "a sequence of requests made by a single end-user during a visit to a particular site".
A more expansive and abstract definition is provided by Doug Lea, whose session design pattern is:
Abstractly, sessions consist of three sets of actions on resources. Call the kinds of actions B, M, and E (for Beginning, Middle, and End). The rules are that
- A session begins with a single B-Action. A B-action normally returns a handle (reference, id, pointer, etc) argument, h.
- Any number of M- actions may occur after the single B-action. Each M- action somehow uses the handle h obtained from the B-action.
- A session ends with a single E-action that somehow invalidates or consumes the handle h. An E-action is triggered only when no additional M-actions are desired or possible.
This simple protocol can be described as the regular expression: (B M* E).[12]
User sessions on Wikipedia meet this definition, because they can be seen as a user coming to Wikipedia in their first request (a B-action), browsing successive pages on the site through internal links (M-actions) and either ending their session by closing the tab or by navigating to a site outside the Wikimedia ecosystem (an E-action). Lea's definition will thus be used.
Identifying a session within a dataset is more difficult. Existing papers and work on web sessions fall largely into two camps. Jansen & Spink's work uses an arbitrary "episode", or "session", which is "a period from the first recorded time stamp to the last recorded time stamp...from a particular [user] on a particular day".[10] Eickhoff et al (2014),[5] on the other hand, draw boundaries after a 30 minute period of inactivity for that user. Both of these identification methods have the problem of being arbitrary, and seem to be measuring something that doesn't resemble what we'd consider a "session"; Jansen's method is measuring by-day user activity and Eickhoff's seems completely arbitrary. In fact, it is completely arbitrary, although it has some pedigree behind it,[13] and Jones & Klinkner (2008)[6] found that "this threshold is no better than random for identifying boundaries between user search tasks". Indeed, Jones & Klinkner tested multiple different arbitrary cutoffs, and found none that were reliable.
So, 24-hour 'episodes' don't tell us what we want, and arbitrary inactivity cutoffs don't either. What's left?
Mehrzadi & Feitelson (2012)[14] investigated a variety of ways of identifying sessions, including the arbitrary cutoffs described above. They also looked at considering the intervals between successive actions. In other words, we assume a unique user would not be engaging in multiple sessions at the same time, and there would be a gap between sessions. As a result, if we look at the time between each request for each client, and aggregate them, we can expect to see a 'drop' at which point most or all users have ended their sessions. Using this data, we identify a local minimum - the first point at which the number of requests drops particularly low - and use that as the cutoff for 'session'. Mehrzadi & Feitelson actually found, using their example dataset, no clear dropoff - but Geiger & Halfaker used it successfully with a dataset of Wikipedia editors, so we can at least experiment with it.
Results
editUsing the fingerprinting algorithm described in RQ1, we took the example dataset of 10,000 IP addresses, identified unique users, and worked out the time elapsed between each request for each user. These were then aggregated.
-
 Fig. 6: Mobile session times, offset from previous, <3000 seconds
Fig. 6: Mobile session times, offset from previous, <3000 seconds -
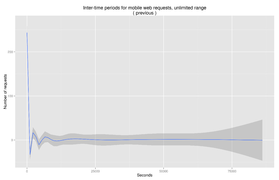 Fig. 7: Mobile session times, offset from previous
Fig. 7: Mobile session times, offset from previous -
 Fig. 8: Mobile session times, offset from previous, log10
Fig. 8: Mobile session times, offset from previous, log10



There is a clear divide between chunks of user actions (Fig. 8), likely indicative of different 'sessions'. When we break the dataset down and look at where the peaks and falls appear, we find that requests tend to near-uniformly cease after 430 seconds of inactivity.(Fig. 6) This is in line with both the results from the ModuleStorage tests in RQ1, and Geiger & Halfaker's work on Wikipedia editors.
Discussion
editLooking at the time intervals between actions, we are able to identify a dataset-specific cutoff point to identify 'sessions' - 430 seconds. This provides a clean breakpoint, and is in line with existing research on session time as applied to Wikipedia.
RQ3: What does session length look like for our mobile interface?
editThanks to RQ1, we have a way of fingerprinting users, enabling some analysis of their behaviour. Thanks to RQ2, we have a way of identifying an appropriate 'breakpoint' for sessions, segmenting the data from each user into discrete sessions. We applied these techniques to all the requests from 50,000 randomly-selected IP addresses, from between 23 and 30 January 2014. We then took the segmented datasets and calculated the 'session time' for each, which is identified as the sum of the time between each action, along with the mean of the time between each action to account for time spent on the final page in the session. This analysis will also be performed on a ModuleStorage dataset to provide a control and contrast; while the error rate of the algorithm is low, the severity of the errors is unknown.
Results
editAfter generating the hashes, those 50,000 IP addresses provided 127,249 unique fingerprints. 41,993 of those were excluded, since they'd only visited one page, and inter-time periods cannot directly be calculated for users in that category. Generating inter-time data showed an appropriate breakpoint of 430-450 seconds,(Fig.10) in line with both the test results and Geiger & Halfaker's previous work.
-
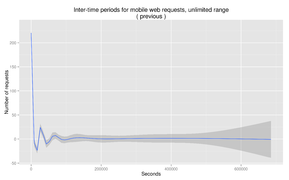 Fig. 9: Time between each request
Fig. 9: Time between each request -
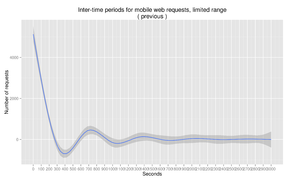 Fig. 10: Time between each request, restricted to entries <3000 seconds
Fig. 10: Time between each request, restricted to entries <3000 seconds


Identifying session time from this segmented dataset, we a distinct long tail,(Fig. 11) which is probably either a genuine long tail caused by a small number of highly active mobile readers or, more likely, given that the highest value would indicate just over 10 hours of continuous browsing, the result of one of the rare 'grouping' errors.
Removing this by restricting the dataset to the 75th percentile and below shows a relatively thick distribution of edit times, peaking in density at around 30-40 seconds, although it can extend as high as 630.(Fig. 12) An alternative way of dealing with the problem - putting the data on a logarithmic scale - shows the peak at around 900 seconds (Fig. 13).
-
 Fig. 11: Total mobile session length
Fig. 11: Total mobile session length -
 Fig. 12: Total mobile session length, 0:75th percentile.
Fig. 12: Total mobile session length, 0:75th percentile. -
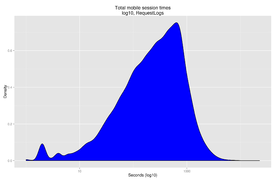 Fig. 13: Total mobile session length, log10 values.
Fig. 13: Total mobile session length, log10 values. -
 Fig. 14: Box plot of time spent on each page in a session, according to the RequestLogs
Fig. 14: Box plot of time spent on each page in a session, according to the RequestLogs




Regardless of which visualisation method is used, the dataset shows a median session time of 256 seconds, over 26,336 observations.
However, when we look at time on individual pages, we see an unexpectedly low median - 13 seconds.(Fig. 14). A likely explanation of this is a weakness in the algorithm unexpectedly grouping users, which leads to an incorrect assessment of time between requests for each user. This can be tested by using the ModuleStorage data as a control.
Retrieving all Mobile ModuleStorage events between 16 and 22 January 2014 provides us with 163,439 unique users, of which 74,676 only make a single appearance and are excluded. Cutting at 430 seconds and analysing it in the same way that the RequestLog dataset was analysed shows higher per-page values, with a median of 48 seconds.(Fig. 18)
-
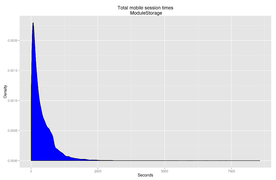 Fig. 15: Total mobile session length, ModuleStorage
Fig. 15: Total mobile session length, ModuleStorage -
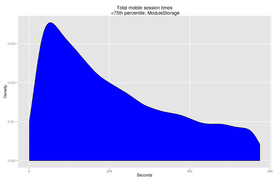 Fig. 16: Total mobile session length, 0:75th percentile, ModuleStorage
Fig. 16: Total mobile session length, 0:75th percentile, ModuleStorage -
 Fig. 17: Total mobile session length, log10 values, ModuleStorage
Fig. 17: Total mobile session length, log10 values, ModuleStorage -
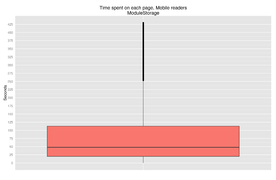 Fig. 18: Box plot of time spent on each page in a session, according to the ModuleStorage dataset.
Fig. 18: Box plot of time spent on each page in a session, according to the ModuleStorage dataset.




{kind=link}
Discussion
editIf we look at data from the RequestLogs, using the fingerprinting algorithm identified in RQ2, we see a median session length of 256 seconds - just over four minutes - with a per-page median of 13 seconds. This feels unlikely, and with the control of the ModuleStorage data, which has a different fingerprinting method, we see a 264-second median session length, with a per-page median of 48 seconds.
Conclusion
editThrough the fingerprinting algorithm in RQ1 and the breakpoint identified in RQ2, we can, in RQ3, clearly identify mobile reader sessions and the approximate length of time users spend on Wikipedia. In addition, we have a way of fingerprinting users from the data in the RequestLogs that is almost as accurate as using cookie identifiers when it comes to session length. At the same time, it provides potentially inaccurate results for per-page timings, and actions within a session. Using ModuleStorage-style fingerprinting instead provides both a control and greater accuracy in this kind of analysis. This opens us up for the kind of analysis mentioned in the introduction - namely, looking at things like topic clustering and the efficacy of our search setup. This could also be used to look at comparisons between mobile and desktop behaviour when evaluating how we approach feature design for mobile, compared to the equivalent feature(s) on desktop.
There are a number of caveats to this, however, and a number of alternative ways of exploring session time analysis. On the caveats front: the need to use intervals at a crucial point in the analysis means that the dataset only includes users who viewed multiple pages in their session. Users who only viewed a single page are quite likely to have different behavioural patterns. While we can estimate their per-page times and session length from the per-page times of readers with multiple pageviews in a session, it's to be expected that single-page readers will have different behavioural patterns. In addition, this analysis only looks at the first session from each user, although there's no reason (other than computing time) that it can't look at all sessions from each user. It also only uses a week's worth of data - we know that there is seasonality in reader numbers, and it is probable that user behaviour is also, to some degree, seasonal. And, finally, the existing ModuleStorage dataset excludes users whose devices do not have LocalStorage - although this is not a blocker on using ModuleStorage-style IDs for future analysis.
We also have other ways of exploring this data that may be worth trying. Although Mehrzadi & Feitelson's fear about not finding a breakpoint was not validated by this dataset, it could still be worth exploring an alternative that they mentioned, namely user-specific breakpoints rather than global breakpoints. However, this would still cause problems with users who only view a single page.
Privacy and Subject Protection
editThe user fingerprinting that formed a part of this research is a legitimate privacy worry; at least in theory (although we wouldn't actually do it) it would allow us to track the reading behaviour of individual users, and to do so through personally identifiable information.
Specific to this project, the datasets that are released (see "Transparency" below) are scrubbed of all potentially identifying information, and cannot be tracked back to individual users. More generally, the Analytics & Research Department is looking at ways of fingerprinting users that are simultaneously more anonymous (not tracking back to any personally identifiable information) and more explicit (meaning that users can opt-out of them at their prerogative). This is likely to be a cookie-based solution, which, as shown in RQ1, should not impede our ability to do this kind of aggregate analysis (in fact, it will actually increase the accuracy!), but will increase the anonymity of our readers and reduce the amount of information we store about them.
Transparency
editAnonymised datasets and the code used to run this analysis are accessible on github
Notes
edit- ↑ ReadWriteWeb - Top Trends of 2012: The Continuing Rapid Growth of Mobile
- ↑ Mashable - 17.4% of Global Web Traffic Comes Through Mobile
- ↑ a b c d Jansen, Bernard J.; Spink, Amanda (June 2003). "An Analysis of Web Documents Retrieved and Viewed". 4th International Conference on Internet Computing.
- ↑ a b c Jansen, Bernard J.; Spink, Amanada. Saracevic, Tefko (2000). "Real life, real users, and real needs: a study and analysis of user queries on the web" (PDF). Information Processing and Management 36. ISSN 0306-4573.
- ↑ a b Eickhoff, Carsten; Teevan, Jaime., White, Ryen., Dumais, Susan. (2014). "Lessons from the Journey: A Query Log Analysis of Within-Session Learning" (PDF). WSDM 2014 (ACM).
- ↑ a b Jones, Rosie; Klinkner, Kristina Lisa (2008). "Beyond the Session Timeout: Automatic Heiarchical Segmentation of Search Topics in Query Logs" (PDF). CIKM 08 (ACM).
- ↑ a b Geiger, R.S.; Halfaker, A. (2014). "Using Edit Sessions to Measure Participation in Wikipedia" (PDF). Proceedings of the 2013 ACM Conference on Computer Supported Cooperative Work (ACM).
- ↑ a b Suneetha, K.R.; Krishnamoorthi, R. (April 2009). "Identifying User Behavior by Analyzing Web Server Access Log File" (PDF). International Journal of Computer Science and Network Security 9 (4). ISSN 1738-7906.
- ↑ Burby, Jason; Brown, Angie, WAA Standards Committee (16 August 2007). Web Analytics Definitions. Web Analytics Association.
- ↑ a b Jansen, Bernard J.; Spink, Amanda (2006). "How are we searching the world wide web? A comparison of nine search engine transaction logs" (PDF). Information Processing and Management 42 (1). ISSN 0306-4573.
- ↑ Arlitt, Martin. "Characterizing Web User Sessions" (PDF). SIGMETRICS Performance Evaluation Review (ACM) 28 (2). ISSN 0163-5999.
- ↑ Lea, Doug. Sessions - design pattern
- ↑ The idea of a 30 minute session stems from a 1994 paper that claimed to find a 25.5 minute timeout. See Catledge, L.; Pitkow, J. (1995). "Characterizing browsing strategies in the world-wide web". Proceedings of the Third International World-Wide Web Conference on Technology, tools and applications 27.
- ↑ Mehrzadi, David; Feitelson, Dror G. (2012). "On Extracting Session Data from Activity Logs". Proceedings of the 5th Annual International Systems and Storage Conference. SYSTOR '12. ACM. ISBN 978-1-4503-1448-0.